El modelo de generación de video de Alibaba Cloud, Wan 2.1 (Wan), ha sido liberado bajo la licencia Apache 2.0. Esta liberación incluye todo el código de inferencia y los pesos para las versiones de 14B y 1.3B de parámetros, que admiten tanto tareas de texto a video como de imagen a video. Desarrolladores de todo el mundo pueden acceder y experimentar con el modelo en GitHub, HuggingFace y la comunidad Modao.
Versiones de Parámetros de Código Abierto del Modelo:
Versión 14B del Modelo Wan 2.1
- Rendimiento: Destaca en la seguimiento de instrucciones, generación de movimientos complejos, modelado físico y generación de texto a video.
- Benchmark: Logró una puntuación total del 86.22% en el conjunto de evaluación autoritativo VBench, superando significativamente a otros modelos como Sora, Luma y Pika, y ocupando el primer lugar.
Versión 1.3B del Modelo Wan 2.1
- Rendimiento: Supera a modelos de código abierto más grandes e incluso iguala a algunos modelos de código cerrado.
- Requisitos de Hardware: Puede ejecutarse en GPUs de consumo con solo 8.2GB de VRAM, capaz de generar videos de 480P.
- Aplicaciones: Adecuado para el desarrollo de modelos secundarios y la investigación académica.
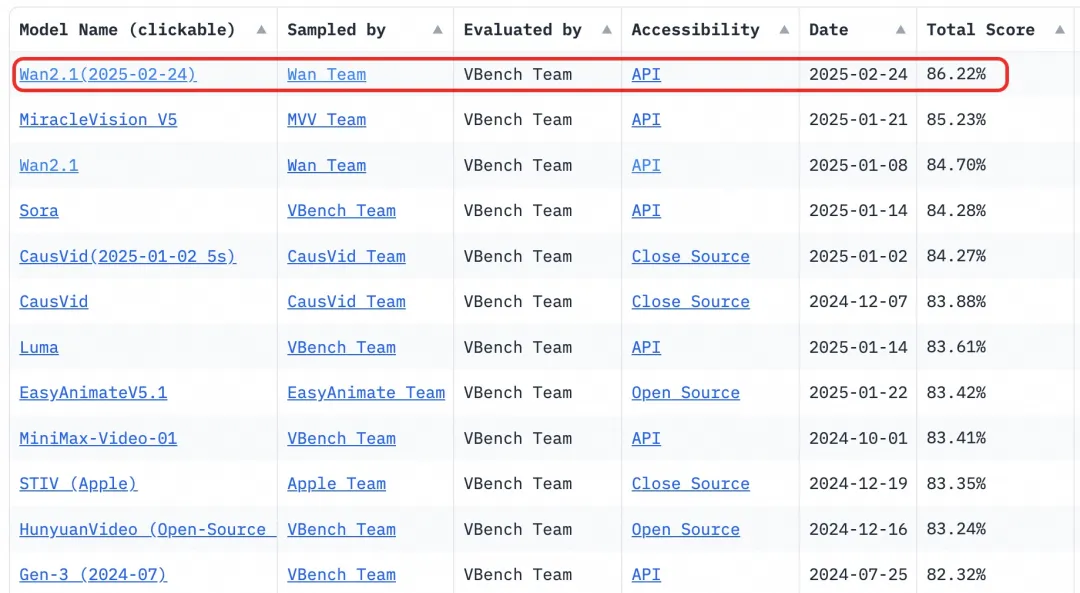
Desde 2023, Alibaba Cloud se ha comprometido a liberar modelos grandes. El número de modelos derivados de Qwen ha superado los 100,000, convirtiéndolo en la familia de modelos de IA más grande del mundo. Con la liberación de Wan 2.1, Alibaba Cloud ha liberado completamente sus dos modelos fundamentales, logrando el estatus de código abierto para modelos grandes multimodales y de escala completa.
Análisis Técnico del Modelo Wan 2.1 (Wan)
Rendimiento del Modelo
El modelo Wan 2.1 supera a los modelos de código abierto existentes y a los principales modelos comerciales de código cerrado en varias pruebas de referencia internas y externas. Puede demostrar de manera estable movimientos complejos del cuerpo humano como giros, saltos, vueltas y rodamientos, y reproducir con precisión escenarios físicos complejos del mundo real como colisiones, rebotes y cortes.

En términos de capacidades de seguimiento de instrucciones, el modelo puede entender con precisión instrucciones textuales largas en chino e inglés, reproduciendo fielmente varias transiciones de escenas e interacciones de personajes.

Tecnologías Clave
Basado en los paradigmas principales de DiT y el esquema de ruido lineal Flow Matching, el Modelo Grande de IA Wan ha logrado avances significativos en capacidades generativas a través de una serie de innovaciones tecnológicas. Estas incluyen el desarrollo de un VAE 3D causal eficiente, estrategias de pre-entrenamiento escalables, la construcción de tuberías de datos a gran escala y la implementación de métricas de evaluación automatizadas. Juntas, estas innovaciones han mejorado el rendimiento general del modelo.
VAE 3D Causal Eficiente: Wan AI ha desarrollado una nueva arquitectura de VAE 3D causal específicamente diseñada para la generación de video, incorporando varias estrategias para mejorar la compresión espacio-temporal, reducir el uso de memoria y garantizar la causalidad temporal.
Video Diffusion Transformer: La arquitectura del modelo Wan AI se basa en la estructura principal de Video Diffusion Transformer. Asegura un modelado efectivo de dependencias espacio-temporales a largo plazo a través del mecanismo de Full Attention, logrando una generación de video temporal y espacialmente consistente.
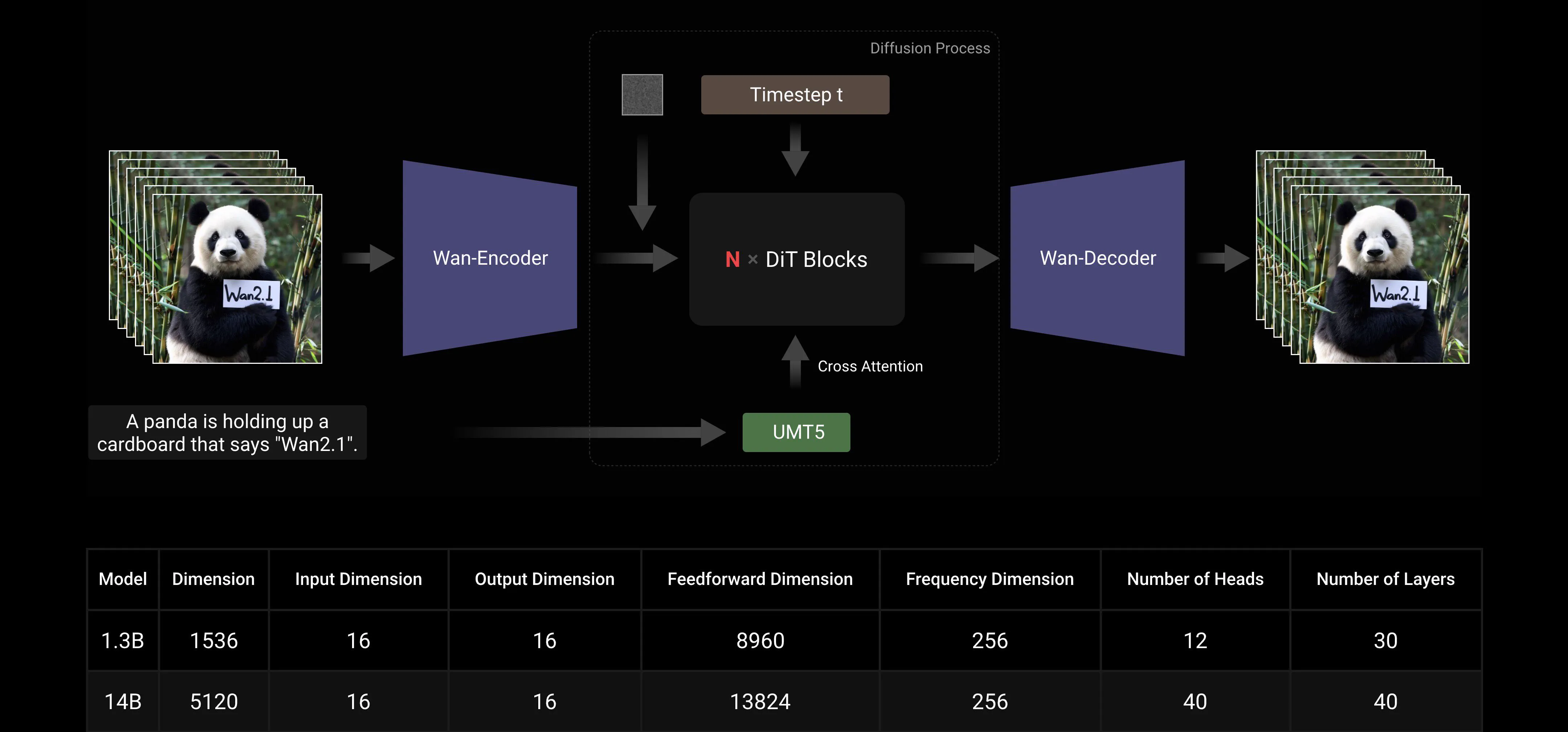
Optimización de Eficiencia en Entrenamiento e Inferencia del Modelo: Durante la fase de entrenamiento, para los módulos de codificación de texto y video, empleamos una estrategia distribuida que combina Paralelismo de Datos (DP) y Paralelismo de Datos Completamente Fragmentado (FSDP). Para el módulo DiT, adoptamos una estrategia de paralelismo híbrido que integra DP, FSDP, RingAttention y Ulysses. Durante la fase de inferencia, para reducir la latencia de generar un solo video usando múltiples GPUs, necesitamos seleccionar Paralelismo Colectivo (CP) para la aceleración distribuida. Además, cuando el modelo es grande, también se requiere el corte del modelo.

Amigable con la Comunidad de Código Abierto
Wan AI ha apoyado completamente múltiples frameworks principales en GitHub y Hugging Face. Ya admite la experiencia de Gradio y la inferencia acelerada en paralelo con xDiT. La integración con Diffusers y ComfyUI también se está implementando rápidamente para facilitar la implementación de inferencia con un solo clic para los desarrolladores. Esto no solo reduce el umbral de desarrollo, sino que también proporciona opciones flexibles para usuarios con diferentes necesidades, ya sea para prototipado rápido o implementación de producción eficiente.
Enlaces de la Comunidad de Código Abierto:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Apéndice: Demostración del Modelo Wan AI
El primer modelo de generación de video que admite la generación de texto en chino y simultáneamente permite la generación de efectos de texto en chino e inglés:
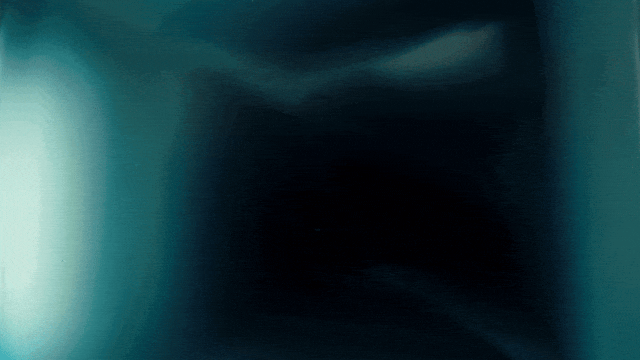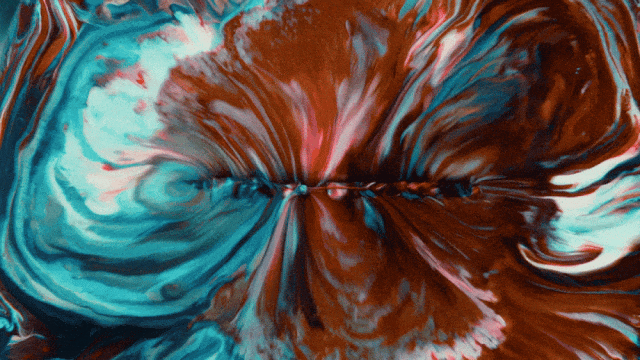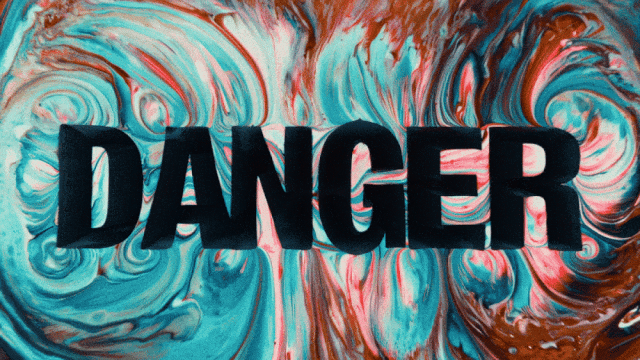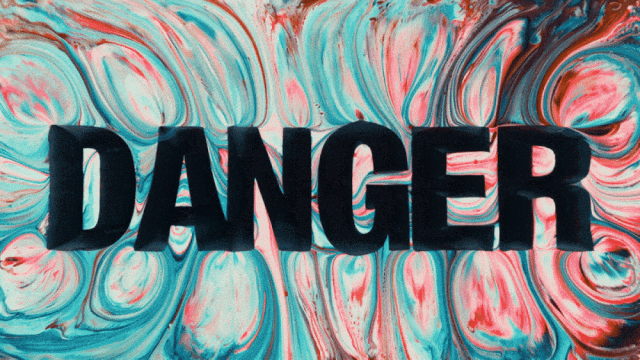
 Capacidades de Generación de Movimientos Más Estables y Complejos:
Capacidades de Generación de Movimientos Más Estables y Complejos:

 Capacidades de Control de Cámara Más Flexibles::
Capacidades de Control de Cámara Más Flexibles::

 Textura Avanzada, Estilos Diversos y Múltiples Relaciones de Aspecto:
Textura Avanzada, Estilos Diversos y Múltiples Relaciones de Aspecto:
 Generación de Imagen a Video, Haciendo la Creación Más Controlable:
Generación de Imagen a Video, Haciendo la Creación Más Controlable:

