O modelo de geração de vídeo da Alibaba Cloud, Wan 2.1 (Wan), foi disponibilizado como código aberto sob a licença Apache 2.0. Este lançamento inclui todo o código de inferência e pesos para as versões de 14B e 1.3B de parâmetros, suportando tarefas de texto para vídeo e imagem para vídeo. Desenvolvedores de todo o mundo podem acessar e experimentar o modelo no GitHub, HuggingFace e na comunidade Modao.
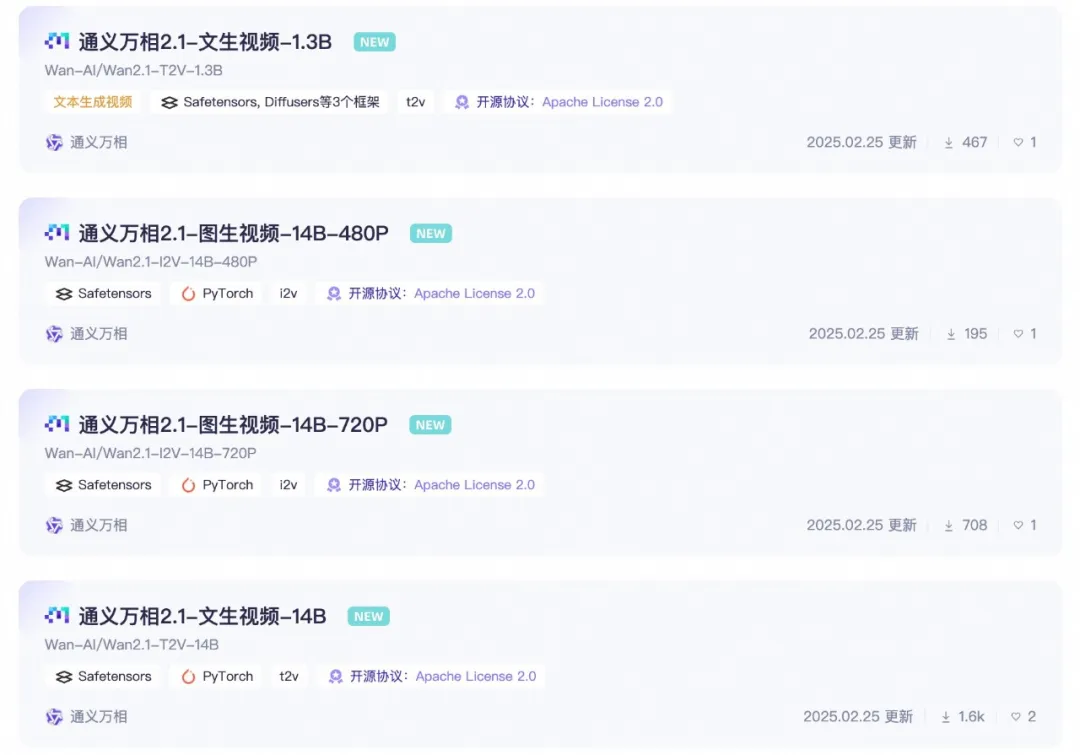
Versões de Parâmetros do Modelo Disponibilizadas como Código Aberto:
Versão 14B do Modelo Wan 2.1
- Desempenho: Destaca-se na execução de instruções, geração de movimentos complexos, modelagem física e geração de texto para vídeo.
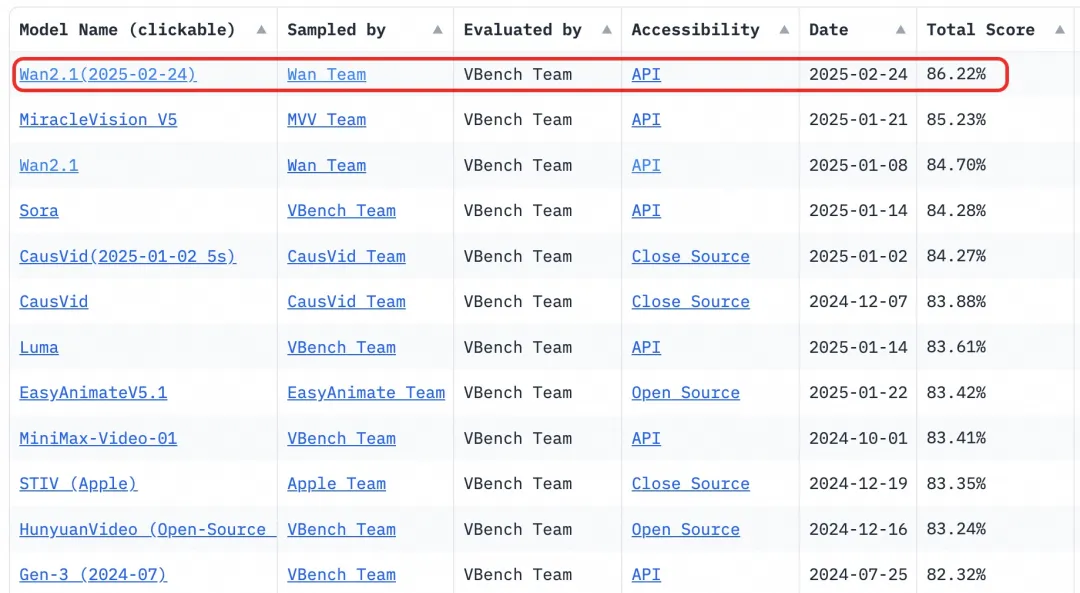
- Benchmark: Alcançou uma pontuação total de 86,22% no conjunto de avaliação VBench, superando significativamente outros modelos como Sora, Luma e Pika, e ficando em primeiro lugar.
Versão 1.3B do Modelo Wan 2.1
- Desempenho: Supera modelos de código aberto maiores e até mesmo alguns modelos proprietários.
- Requisitos de Hardware: Pode ser executado em GPUs de consumo com apenas 8,2GB de VRAM, capaz de gerar vídeos de 480P.
- Aplicações: Adequado para desenvolvimento de modelos secundários e pesquisa acadêmica.
Desde 2023, a Alibaba Cloud tem se comprometido a disponibilizar grandes modelos como código aberto. O número de modelos derivados do Qwen ultrapassou 100.000, tornando-se a maior família de modelos de IA globalmente. Com a disponibilização do Wan 2.1, a Alibaba Cloud agora disponibilizou completamente seus dois modelos fundamentais, alcançando o status de código aberto para modelos multimodais e de grande escala.
Análise Técnica do Modelo Wan 2.1 (Wan)
Desempenho do Modelo
O modelo Wan 2.1 supera os modelos de código aberto existentes e os principais modelos proprietários comerciais em vários testes de benchmark internos e externos. Ele pode demonstrar de forma estável movimentos complexos do corpo humano, como giros, saltos, viradas e rolos, e reproduzir com precisão cenários físicos complexos do mundo real, como colisões, rebotes e cortes.

Em termos de capacidades de execução de instruções, o modelo pode entender com precisão instruções textuais longas em chinês e inglês, reproduzindo fielmente várias transições de cena e interações de personagens.

Tecnologias-Chave
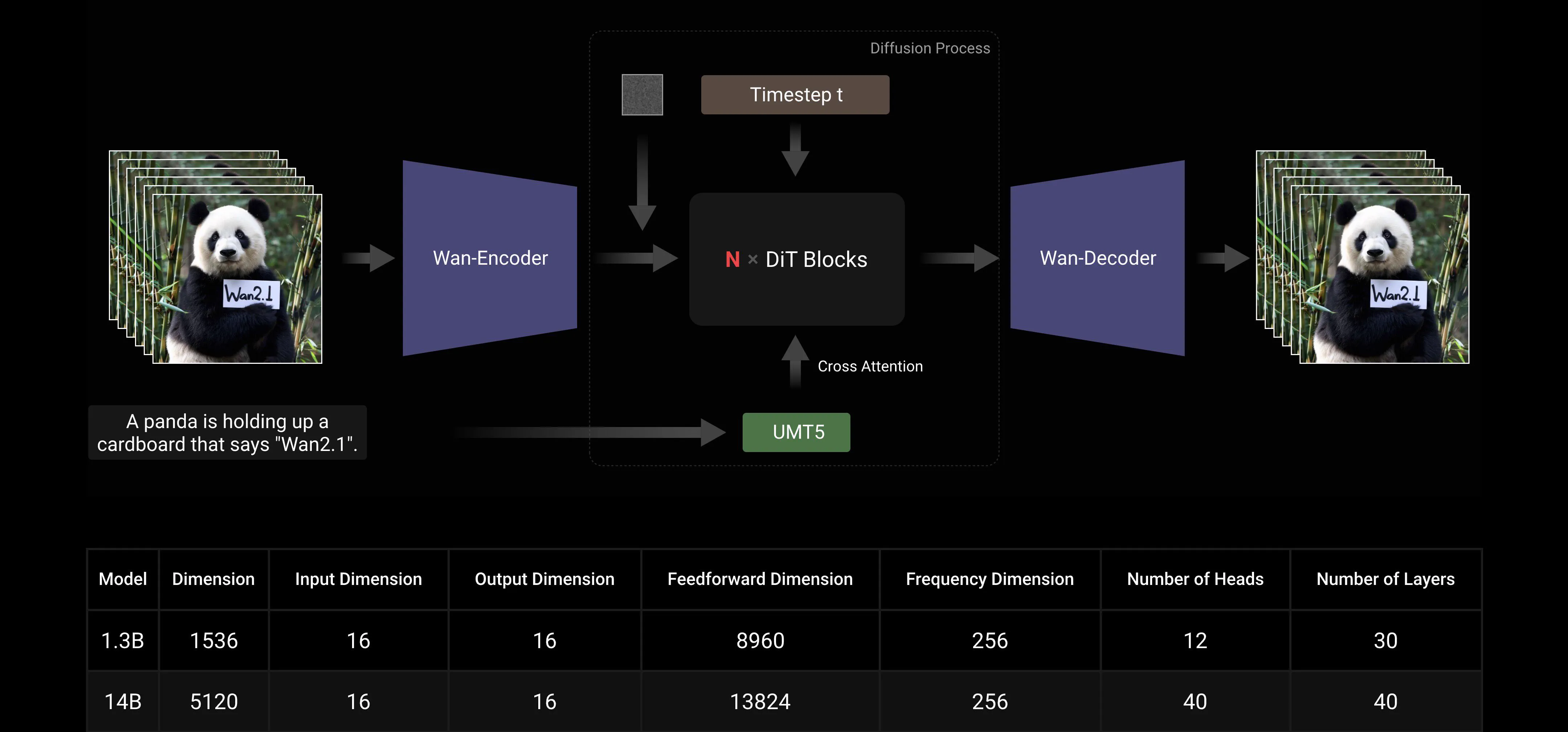
Baseado nos paradigmas mainstream de DiT e linear noise schedule Flow Matching, o Wan AI Large Model alcançou progressos significativos em capacidades generativas através de uma série de inovações tecnológicas. Estas incluem o desenvolvimento de um eficiente 3D VAE causal, estratégias de pré-treinamento escaláveis, a construção de pipelines de dados em grande escala e a implementação de métricas de avaliação automatizadas. Juntas, essas inovações melhoraram o desempenho geral do modelo.
Efficient Causal 3D VAE: O Wan AI desenvolveu uma nova arquitetura de 3D VAE causal especificamente projetada para geração de vídeo, incorporando várias estratégias para melhorar a compressão espaço-temporal, reduzir o uso de memória e garantir a causalidade temporal.
Video Diffusion Transformer: A arquitetura do modelo Wan AI é baseada na estrutura mainstream de Video Diffusion Transformer. Ela garante a modelagem eficaz de dependências espaço-temporais de longo prazo através do mecanismo Full Attention, alcançando geração de vídeo temporal e espacialmente consistente.
Otimização de Eficiência de Treinamento e Inferência do Modelo: Durante a fase de treinamento, para os módulos de codificação de texto e vídeo, empregamos uma estratégia distribuída combinando Data Parallelism (DP) e Fully Sharded Data Parallelism (FSDP). Para o módulo DiT, adotamos uma estratégia híbrida de paralelismo que integra DP, FSDP, RingAttention e Ulysses. Durante a fase de inferência, para reduzir a latência de geração de um único vídeo usando múltiplas GPUs, precisamos selecionar Collective Parallelism (CP) para aceleração distribuída. Além disso, quando o modelo é grande, o fatiamento do modelo também é necessário.

Amigável à Comunidade de Código Aberto
O Wan AI suporta totalmente múltiplos frameworks mainstream no GitHub e Hugging Face. Ele já suporta a experiência Gradio e inferência acelerada em paralelo com xDiT. A integração com Diffusers e ComfyUI também está sendo rapidamente implementada para facilitar a implantação de inferência com um clique para desenvolvedores. Isso não apenas reduz o limiar de desenvolvimento, mas também fornece opções flexíveis para usuários com diferentes necessidades, seja para prototipagem rápida ou implantação eficiente de produção.
Links da Comunidade de Código Aberto:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Apêndice: Demonstração do Modelo Wan AI
O primeiro modelo de geração de vídeo que suporta geração de texto em chinês e simultaneamente permite geração de efeitos de texto em chinês e inglês:
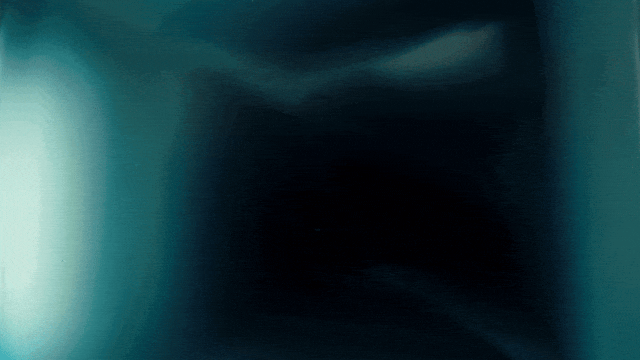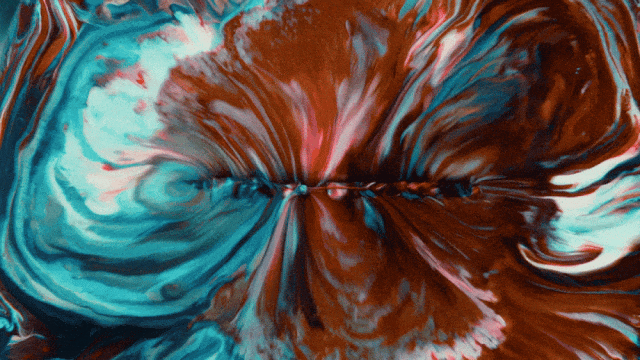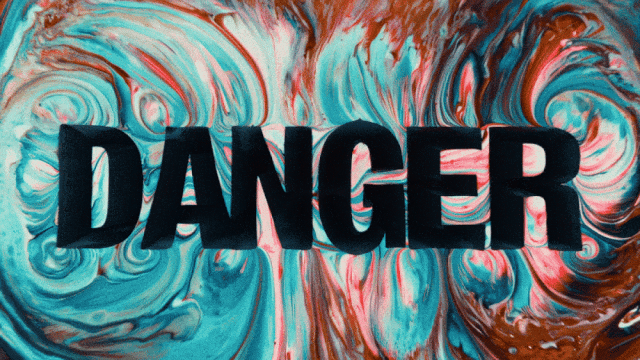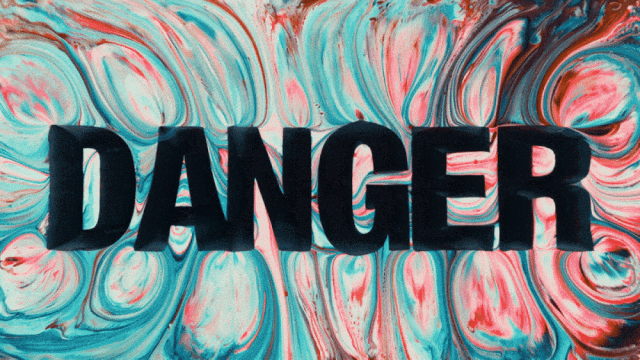
 Capacidades de Geração de Movimento Mais Estáveis e Complexas:
Capacidades de Geração de Movimento Mais Estáveis e Complexas:

 Capacidades de Controle de Câmera Mais Flexíveis::
Capacidades de Controle de Câmera Mais Flexíveis::

 Textura Avançada, Estilos Diversos e Múltiplas Proporções:
Textura Avançada, Estilos Diversos e Múltiplas Proporções:
 Geração de Imagem para Vídeo, Tornando a Criação Mais Controlável:
Geração de Imagem para Vídeo, Tornando a Criação Mais Controlável:

