Model generowania wideo Alibaba Cloud, Wan 2.1 (Wan), został udostępniony na licencji Apache 2.0. Ta wersja zawiera cały kod inferencyjny oraz wagi dla wersji z 14B i 1.3B parametrów, obsługując zarówno zadania tekst-na-wideo, jak i obraz-na-wideo. Programiści na całym świecie mogą uzyskać dostęp do modelu i go przetestować na GitHub, HuggingFace oraz społeczności Modao.
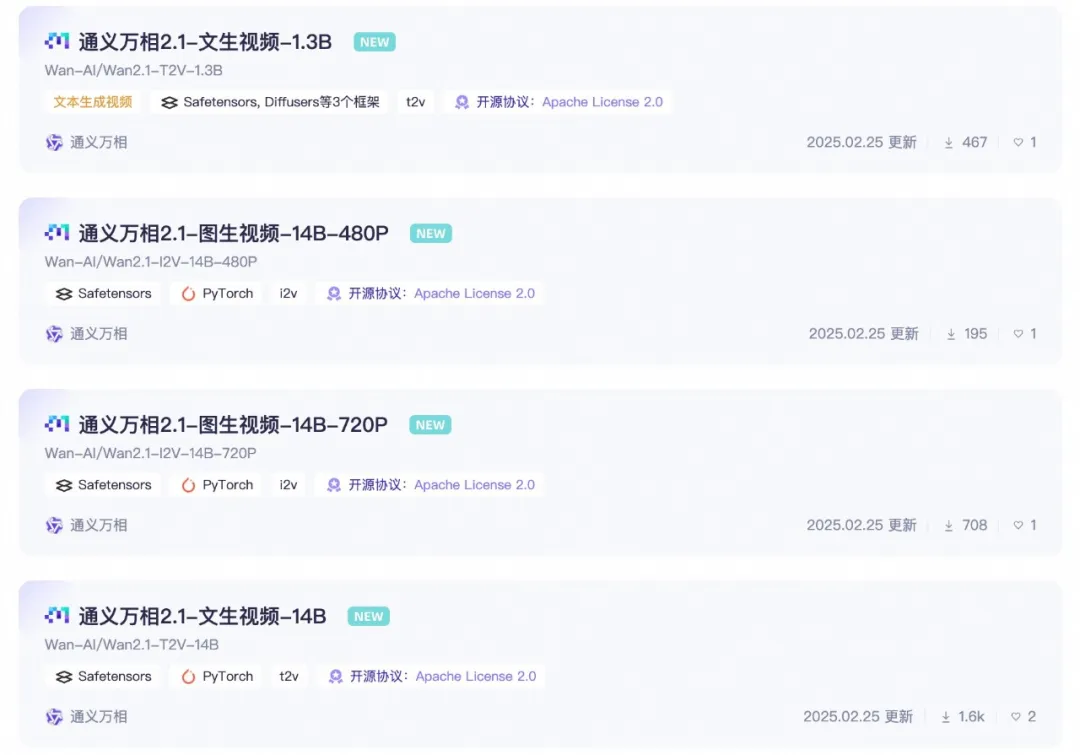
Udostępnione wersje parametrów modelu:
Wersja 14B modelu Wan 2.1
- Wydajność: Wyróżnia się w zakresie wykonywania instrukcji, generowania złożonych ruchów, modelowania fizycznego oraz generowania wideo z tekstu.
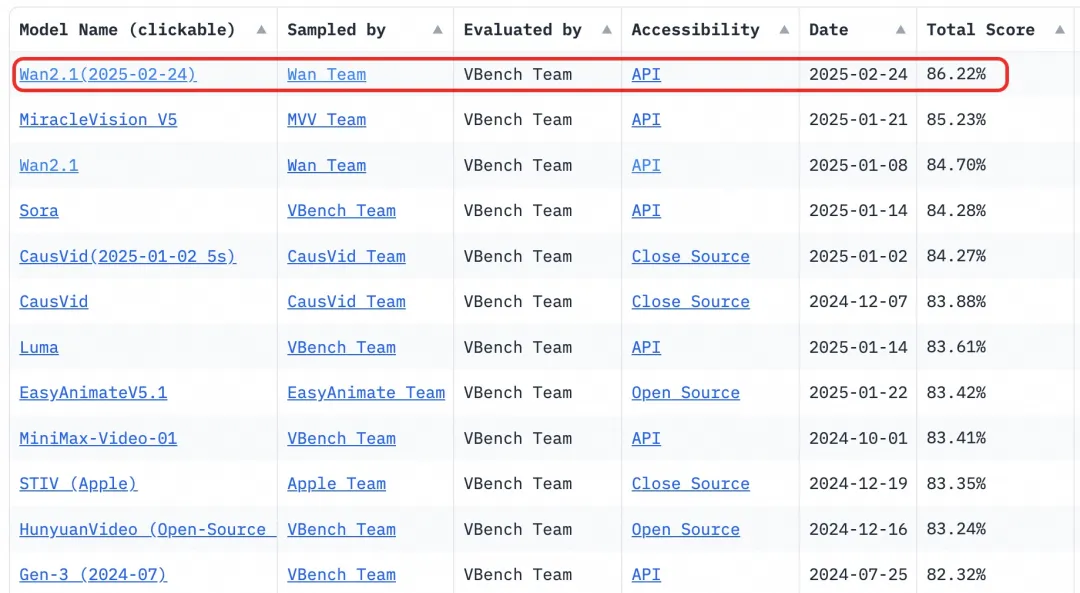
- Benchmark: Osiągnął łączny wynik 86.22% w autorytatywnym zestawie oceny VBench, znacznie przewyższając inne modele, takie jak Sora, Luma i Pika, i zajmując pierwsze miejsce.
Wersja 1.3B modelu Wan 2.1
- Wydajność: Przewyższa większe modele open-source, a nawet dorównuje niektórym zamkniętym modelom.
- Wymagania sprzętowe: Może działać na konsumenckich kartach graficznych z zaledwie 8.2GB pamięci VRAM, generując wideo w rozdzielczości 480P.
- Zastosowania: Nadaje się do rozwoju modeli wtórnych i badań akademickich.
Od 2023 roku Alibaba Cloud jest zaangażowana w udostępnianie dużych modeli. Liczba modeli pochodnych Qwen przekroczyła 100 000, czyniąc go największą rodziną modeli AI na świecie. Dzięki udostępnieniu Wan 2.1, Alibaba Cloud w pełni udostępniła swoje dwa podstawowe modele, osiągając status open-source dla multimodalnych, pełnowymiarowych dużych modeli.
Analiza techniczna modelu Wan 2.1 (Wan)
Wydajność modelu
Model Wan 2.1 przewyższa istniejące modele open-source oraz najlepsze komercyjne modele zamknięte w różnych testach benchmarkowych. Może stabilnie demonstrować złożone ruchy ludzkiego ciała, takie jak obroty, skoki, zwroty i przewroty, oraz dokładnie odtwarzać złożone scenariusze fizyczne, takie jak kolizje, odbicia i cięcia.

Pod względem zdolności do wykonywania instrukcji, model może dokładnie rozumieć długie instrukcje tekstowe w języku chińskim i angielskim, wiernie odtwarzając różne przejścia scen i interakcje postaci.

Kluczowe technologie
Opierając się na głównych paradygmatach DiT i liniowego harmonogramu szumu Flow Matching, Wan AI Large Model osiągnął znaczący postęp w zakresie zdolności generatywnych dzięki serii innowacji technologicznych. Obejmują one rozwój wydajnego przyczynowego 3D VAE, skalowalne strategie pre-treningu, budowę dużych potoków danych oraz wdrożenie zautomatyzowanych metryk oceny. Wspólnie te innowacje poprawiły ogólną wydajność modelu.
Wydajny przyczynowy 3D VAE: Wan AI opracował nową architekturę przyczynowego 3D VAE specjalnie zaprojektowaną do generowania wideo, włączając różne strategie poprawiające kompresję czasoprzestrzenną, redukujące użycie pamięci i zapewniające przyczynowość czasową.
Video Diffusion Transformer: Architektura modelu Wan AI opiera się na głównej strukturze Video Diffusion Transformer. Zapewnia skuteczne modelowanie długoterminowych zależności czasoprzestrzennych poprzez mechanizm Full Attention, osiągając spójne czasowo i przestrzennie generowanie wideo.
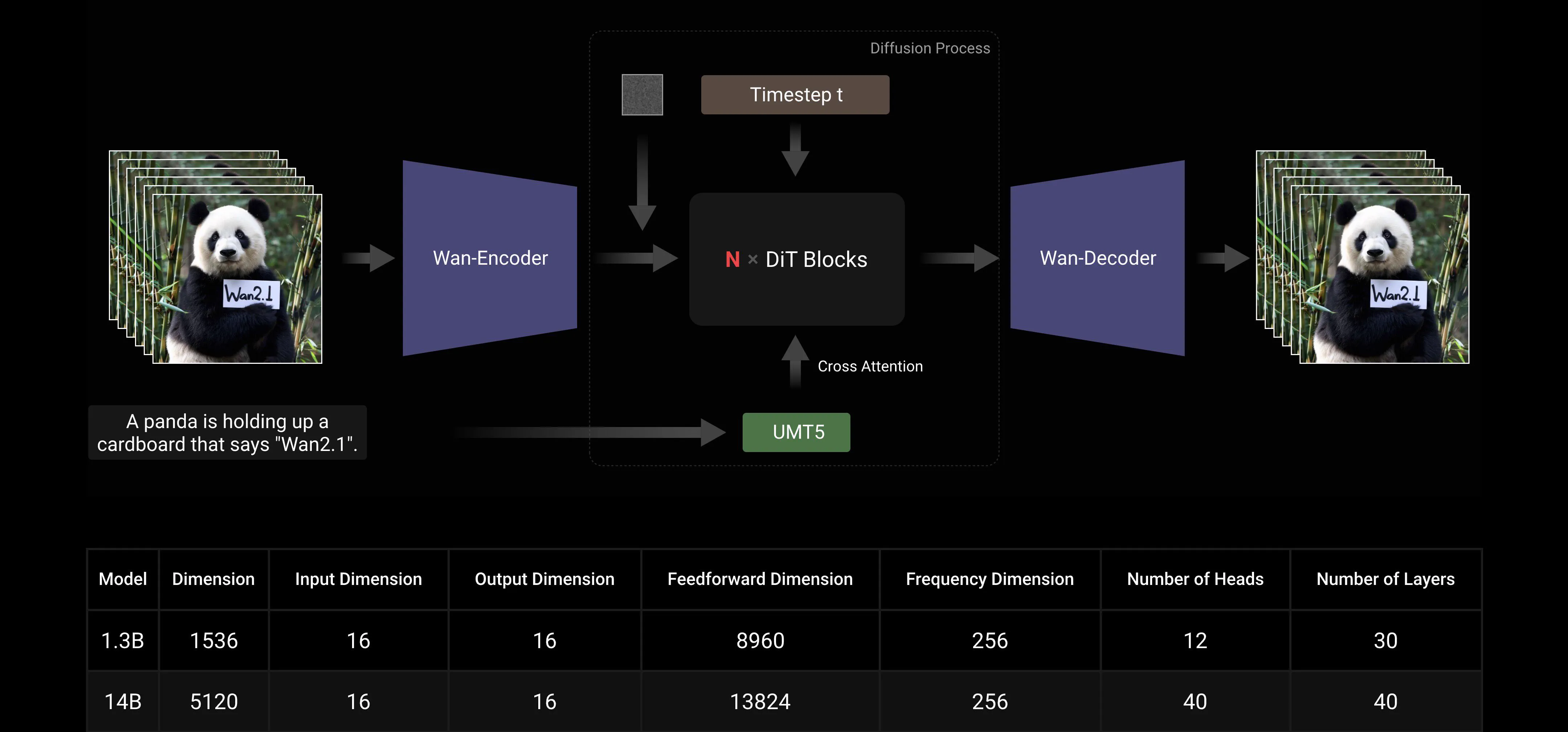
Optymalizacja efektywności treningu i inferencji modelu: Podczas fazy treningowej, dla modułów kodowania tekstu i wideo, stosujemy strategię rozproszoną łączącą Data Parallelism (DP) i Fully Sharded Data Parallelism (FSDP). Dla modułu DiT przyjmujemy hybrydową strategię równoległą integrującą DP, FSDP, RingAttention i Ulysses. Podczas fazy inferencji, aby zmniejszyć opóźnienie generowania pojedynczego wideo przy użyciu wielu GPU, musimy wybrać Collective Parallelism (CP) dla przyspieszenia rozproszonego. Dodatkowo, gdy model jest duży, wymagane jest również dzielenie modelu.

Przyjazność dla społeczności open-source
Wan AI w pełni wspiera wiele głównych frameworków na GitHub i Hugging Face. Już teraz obsługuje doświadczenie Gradio i równoległe przyspieszone wnioskowanie z xDiT. Integracja z Diffusers i ComfyUI jest również szybko wdrażana, aby ułatwić programistom wdrożenie inferencji jednym kliknięciem. To nie tylko obniża próg rozwoju, ale także zapewnia elastyczne opcje dla użytkowników o różnych potrzebach, czy to do szybkiego prototypowania, czy efektywnego wdrażania produkcji.
Linki do społeczności open-source:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Załącznik: Pokaz demo modelu Wan AI
Pierwszy model generowania wideo, który obsługuje generowanie tekstu w języku chińskim i jednocześnie umożliwia generowanie efektów tekstowych w języku chińskim i angielskim:
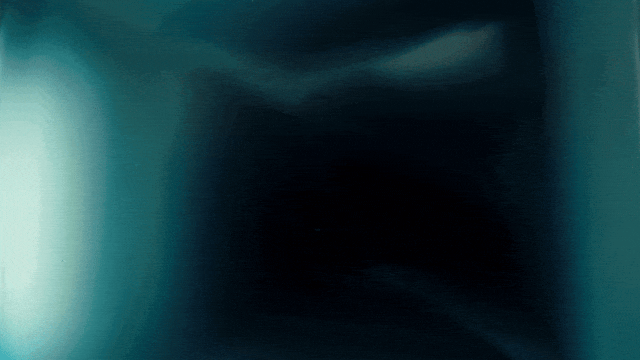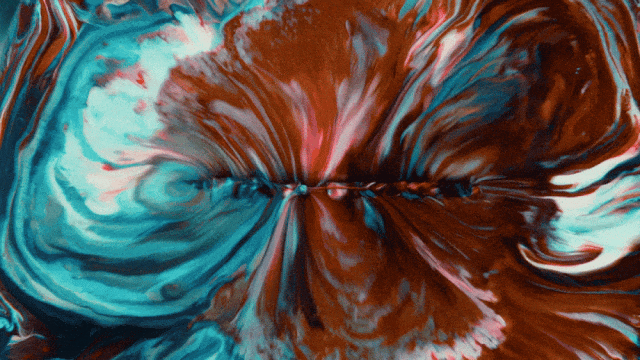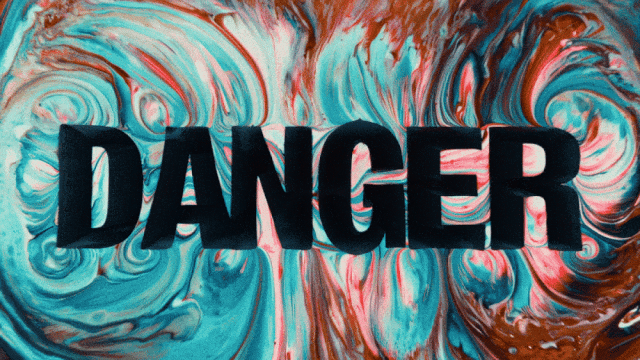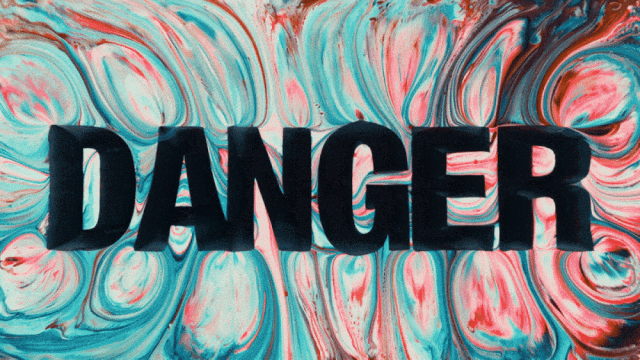
 Bardziej stabilne i złożone możliwości generowania ruchu:
Bardziej stabilne i złożone możliwości generowania ruchu:

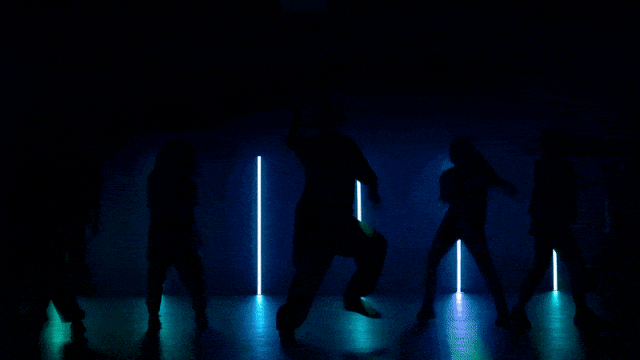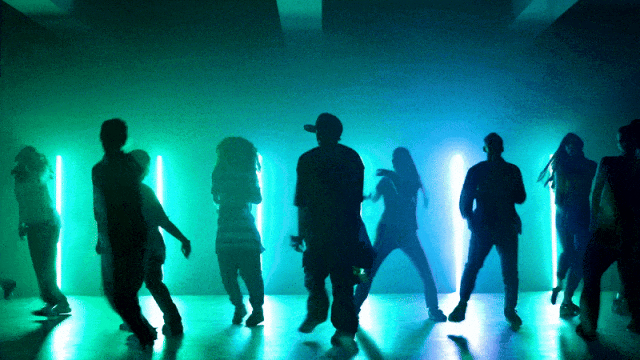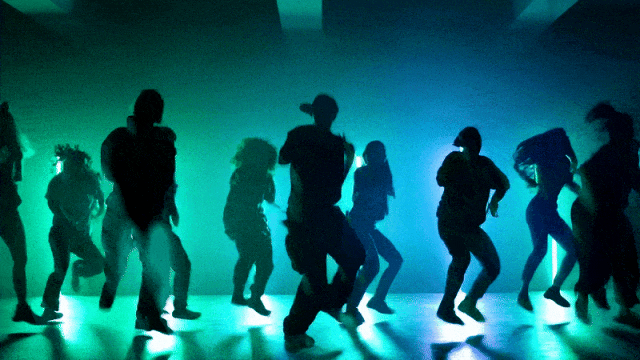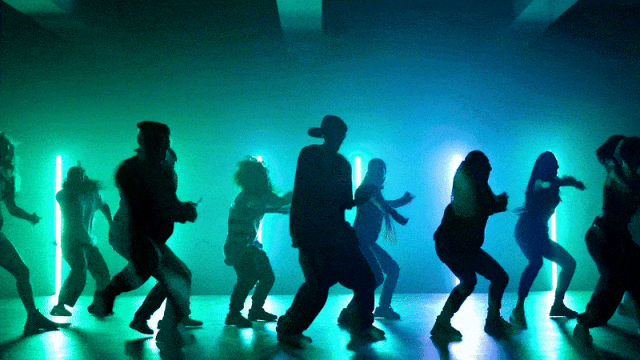 Bardziej elastyczne możliwości kontroli kamery::
Bardziej elastyczne możliwości kontroli kamery::

 Zaawansowane tekstury, różnorodne style i wiele proporcji aspektowych:
Zaawansowane tekstury, różnorodne style i wiele proporcji aspektowych:
 Generowanie wideo z obrazu, czyniąc tworzenie bardziej kontrolowalnym:
Generowanie wideo z obrazu, czyniąc tworzenie bardziej kontrolowalnym:

