Raport Techniczny
Zostań z nami, aby poznać szczegóły w naszym nadchodzącym kompleksowym raporcie technicznym.
Oparty na głównym paradygmacie transformatorów dyfuzyjnych, Wan 2.1 osiąga znaczące postępy w zdolnościach generowania dzięki serii innowacji, w tym naszego nowatorskiego spatiotemporalnego autoenkodera wariacyjnego (VAE), skalowalnych strategii pre-treningowych, budowy danych w dużej skali i automatycznych metryk oceny. Te wkłady zbiorowo poprawiają wydajność i wszechstronność modelu.
Autoenkodery Wariacyjne 3D
Proponujemy nową architekturę VAE kauzalnego 3D zaprojektowaną specjalnie do generowania wideo. Łączymy wiele strategii, aby poprawić kompresję spatiotemporalną, zmniejszyć zużycie pamięci i zapewnić kauzalność czasową. Te ulepszenia czynią nasz VAE nie tylko bardziej efektywnym i skalowalnym, ale także lepiej dostosowanym do integracji z generatywnymi modelami opartymi na dyfuzji, takimi jak DiT.
Aby wspierać wydajne kodowanie i dekodowanie wideo dowolnej długości, implementujemy mechanizm buforowania cech wewnątrz modułu konwolucji kauzalnej 3D VAE. W szczególności liczba klatek sekwencji wideo odpowiada formatowi wejściowemu 1 + T, więc dzielimy wideo na fragmenty 1 + T/4, co jest zgodne z liczbą ukrytych cech. Podczas przetwarzania sekwencji wideo wejściowych model używa strategii fragmentowej, w której każda operacja kodowania i dekodowania obsługuje tylko część wideo odpowiadającą pojedynczej ukrytej reprezentacji. Na podstawie współczynnika kompresji czasowej liczba klatek w każdym fragmencie przetwarzania jest ograniczona do maksymalnie 4, co skutecznie zapobiega przeciążeniu pamięci GPU.
Wyniki eksperymentalne wskazują, że nasz VAE wideo wykazuje bardzo konkurencyjną wydajność w obu metrykach, prezentując przekonującą kombinację wyższej jakości wideo i wysokiej wydajności przetwarzania. Warto zauważyć, że w tym samym środowisku sprzętowym (tj. pojedyncza GPU A800) prędkość rekonstrukcji naszego VAE jest 2,5 razy szybsza niż istniejącej metody SOTA (tj. HunYuanVideo). Ta przewaga wydajności będzie jeszcze bardziej widoczna przy wyższych rozdzielczościach ze względu na kompaktowy projekt naszego modelu VAE i mechanizm buforowania cech.
Dyfuzja Wideo DiT
Wan AI 2.1 jest zaprojektowany z użyciem ramy Flow Matching w ramach głównego paradygmatu transformatorów dyfuzyjnych. W architekturze naszego modelu używamy enkodera T5 do kodowania wielojęzycznego tekstu wejściowego, włączając uwagę krzyżową w każdy blok transformatora, aby osadzić tekst w strukturze modelu. Ponadto używamy warstwy liniowej i warstwy SiLU do przetwarzania osadzeń czasowych wejściowych i przewidywania sześciu parametrów modulacji indywidualnie. Ten MLP jest współdzielony między wszystkimi blokami transformatorów, przy czym każdy blok uczy oddzielny zestaw wartości przestrzennych. Nasze wyniki eksperymentalne pokazują znaczącą poprawę wydajności z tym podejściem przy tej samej skali parametrów. Dlatego implementujemy tę architekturę zarówno w modelu 1.3B, jak i 14B.
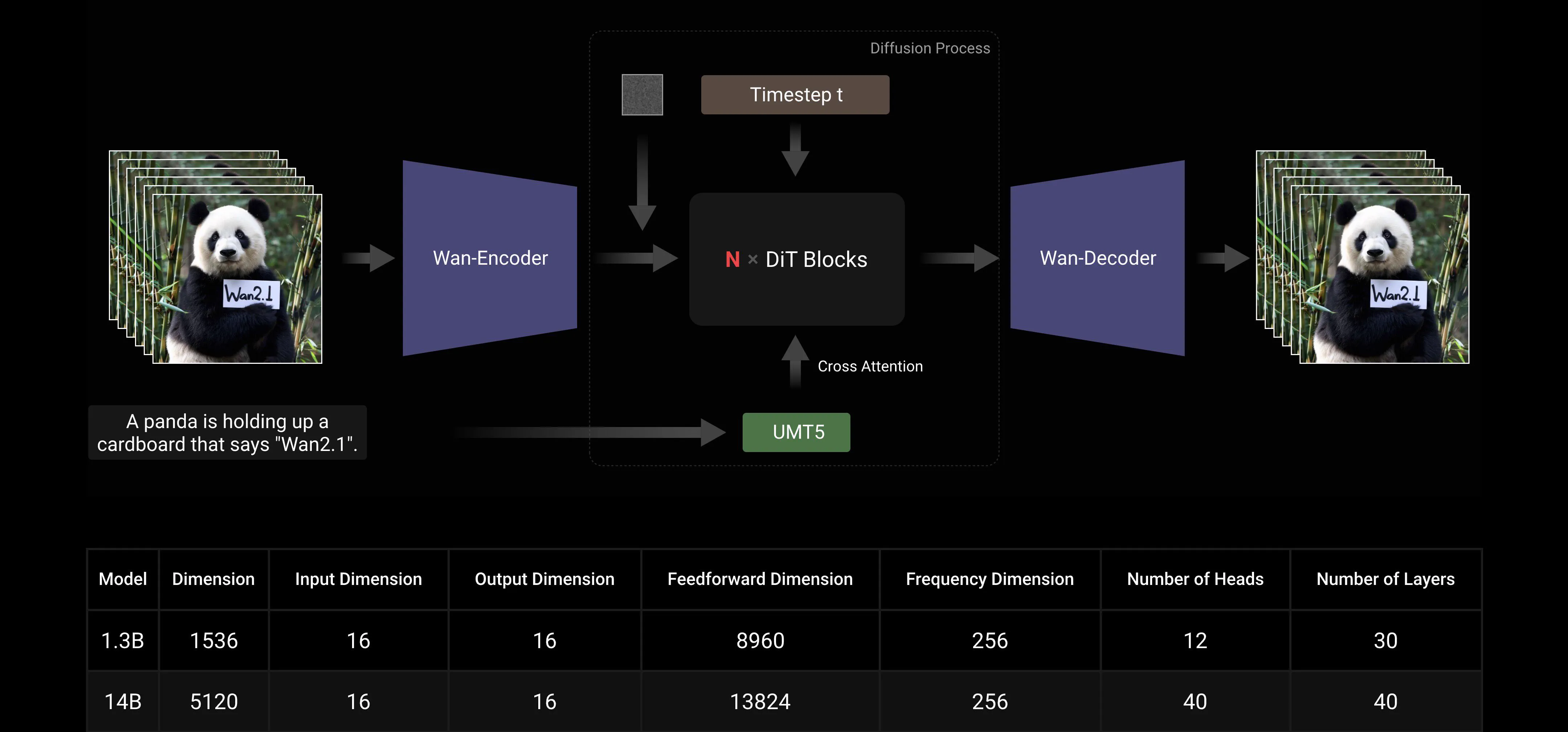
Skalowalność Modelu i Efektywność Treningu
Podczas treningu używamy FSDP do dzielenia modelu, w połączeniu z równoległością kontekstową (CP), grupa FSDP i grupa CP przecinają się zamiast tworzyć zagnieżdżone połączenie równoległości modelu (MP) i CP/DP. W ramach FSDP rozmiar DP jest równy rozmiarowi FSDP podzielonemu przez rozmiar CP. Po spełnieniu wymagań dotyczących pamięci i opóźnienia jednej partii, używamy DP do skalowania.
Podczas inferencji, aby zmniejszyć opóźnienie generowania pojedynczego wideo podczas skalowania na wiele GPU, należy wybrać równoległość kontekstową do przyspieszenia dystrybuowanego. Ponadto, gdy model jest duży, wymagane jest dzielenie modelu.
Strategia Dzielenia Modelu: Dla dużych modeli, takich jak 14B, należy uwzględnić dzielenie modelu. Ponieważ długości sekwencji są zwykle długie, FSDP powoduje mniejsze obciążenie komunikacyjne niż TP i pozwala na nakładanie się obliczeń. Dlatego wybieramy metodę FSDP do dzielenia modelu, zgodnie z naszym podejściem treningowym (uwaga: tylko dzielenie wag bez implementacji równoległości danych).
Strategia Równoległości Kontekstowej: Wykorzystanie tej samej metody równoległości kontekstowej 2D co podczas treningu: zastosowanie RingAttention dla warstwy zewnętrznej (inter-machine) i Ulysses dla warstwy wewnętrznej (intra-machine).
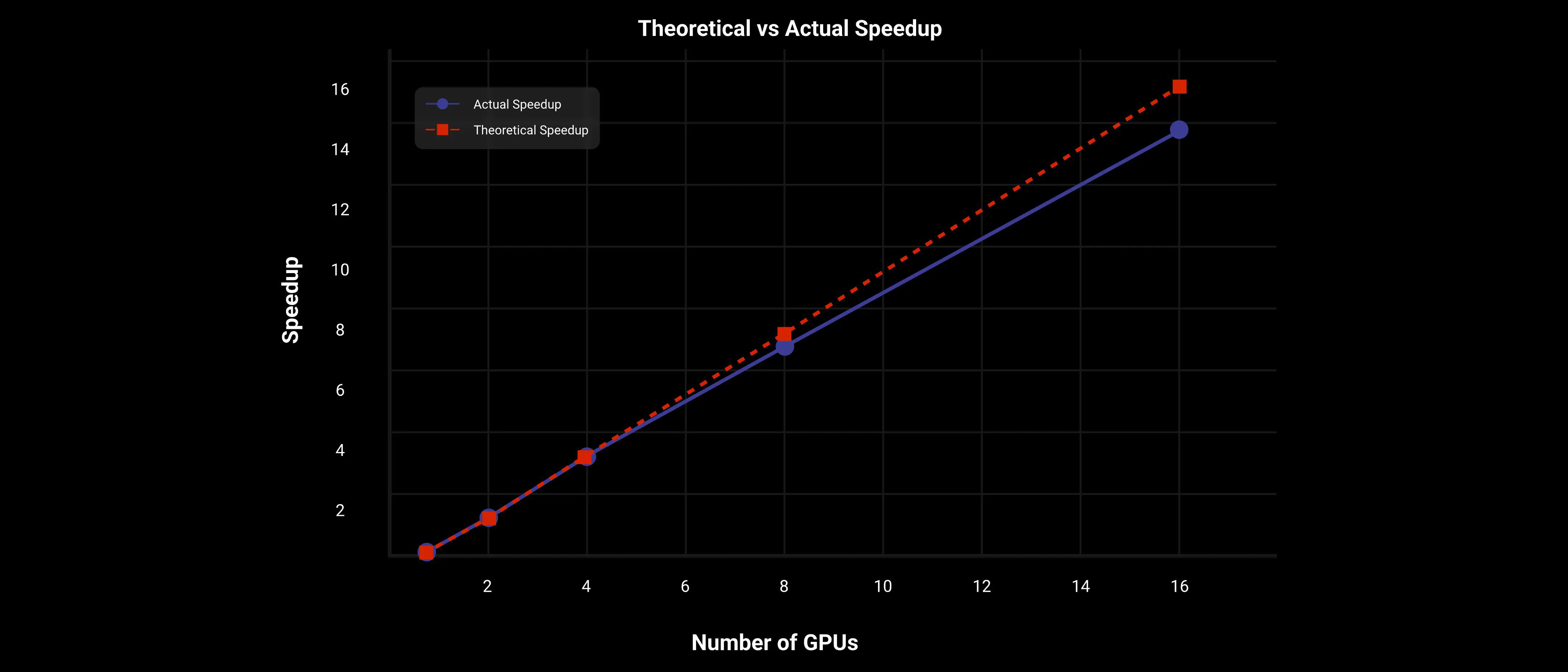
Z podejściem równoległości kontekstowej 2D i FSDP, DiT osiąga prawie liniowe przyspieszenie na dużym modelu Wan AI 2.1 14B, jak pokazano na poniższym rysunku.
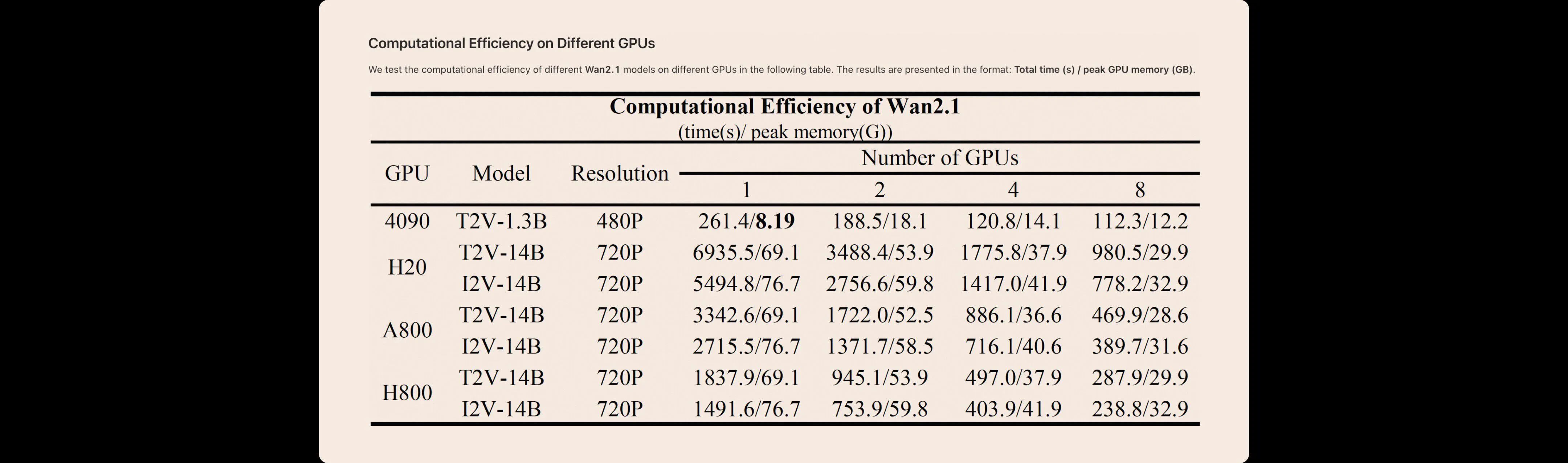
Testujemy wydajność obliczeniową różnych modeli Wan AI 2.1 na różnych GPU w poniższej tabeli. Wyniki są przedstawione w formacie: całkowity czas (s) / maksymalna pamięć GPU (GB).
Obraz do Wideo
Zadanie Obraz do Wideo (I2V) ma na celu animowanie danego obrazu w wideo na podstawie podpowiedzi wejściowej, co poprawia sterowalność generowania wideo. Wprowadzamy dodatkowy obraz warunkowy jako pierwszą klatkę, aby kontrolować syntezę wideo. W szczególności obraz warunkowy jest łączony z klatkami wypełnionymi zerami wzdłuż osi czasowej, tworząc klatki przewodnie. Te klatki przewodnie są następnie kompresowane przez autoenkoder wariacyjny 3D (VAE) do ukrytej reprezentacji warunkowej. Ponadto wprowadzamy binarną maskę, gdzie 1 wskazuje zachowaną klatkę, a 0 wskazuje klatki do wygenerowania. Rozmiar przestrzenny maski odpowiada reprezentacji warunkowej ukrytej, ale maska dzieli tę samą długość czasową co docelowe wideo. Ta maska jest następnie przekształcana w specyficzną formę odpowiadającą krokowi czasowemu VAE. Reprezentacja ukryta szumów, reprezentacja warunkowa ukryta i przekształcona maska są łączone wzdłuż wymiaru kanału i przekazywane przez zaproponowany model DiT. Ponieważ wejście do modelu DiT I2V ma więcej kanałów niż model Tekst do Wideo (T2V), używa się dodatkowej warstwy projekcji, zainicjowanej wartościami zerowymi. Ponadto używamy enkodera obrazów CLIP do ekstrakcji reprezentacji cech z obrazu warunkowego. Te wyodrębnione cechy są projektowane przez trzywarstwowy perceptron wielowarstwowy (MLP), który służy jako globalny kontekst. Ten globalny kontekst jest następnie wstrzykiwany do modelu DiT poprzez rozłączoną uwagę krzyżową.
Dane
Kurujemy i deduplikujemy zbiór danych kandydujących składający się z 1,5 miliarda filmów i 10 miliardów obrazów, pochodzących zarówno z wewnętrznych źródeł chronionych prawami autorskimi, jak i danych publicznie dostępnych. W fazie pre-treningowej naszym celem jest wybranie wysokiej jakości i różnorodnych danych z tego rozległego, ale szumnego zbioru danych, aby ułatwić skuteczne trenowanie. Podczas procesu wydobycia danych opracowujemy czteroetapowy proces oczyszczania danych, koncentrując się na podstawowych wymiarach, jakości wizualnej i jakości ruchu.
Porównania z SOTA
Kurujemy i deduplikujemy zbiór danych kandydujących składający się z 1,5 miliarda filmów i 10 miliardów obrazów, pochodzących zarówno z wewnętrznych źródeł chronionych prawami autorskimi, jak i danych publicznie dostępnych. W fazie pre-treningowej naszym celem jest wybranie wysokiej jakości i różnorodnych danych z tego rozległego, ale szumnego zbioru danych, aby ułatwić skuteczne trenowanie. Podczas procesu wydobycia danych opracowujemy czteroetapowy proces oczyszczania danych, koncentrując się na podstawowych wymiarach, jakości wizualnej i jakości ruchu.
Testujemy wydajność obliczeniową różnych modeli Wan AI 2.1 na różnych GPU w poniższej tabeli. Wyniki są przedstawione w formacie: całkowity czas (s) / maksymalna pamięć GPU (GB).