Il modello di generazione video di Alibaba Cloud, Wan 2.1 (Wan), è stato open-source sotto la licenza Apache 2.0. Questa release include tutto il codice di inferenza e i pesi per le versioni da 14B e 1.3B parametri, supportando sia i task di testo-a-video che di immagine-a-video. Gli sviluppatori di tutto il mondo possono accedere e sperimentare il modello su GitHub, HuggingFace e la comunità Modao.
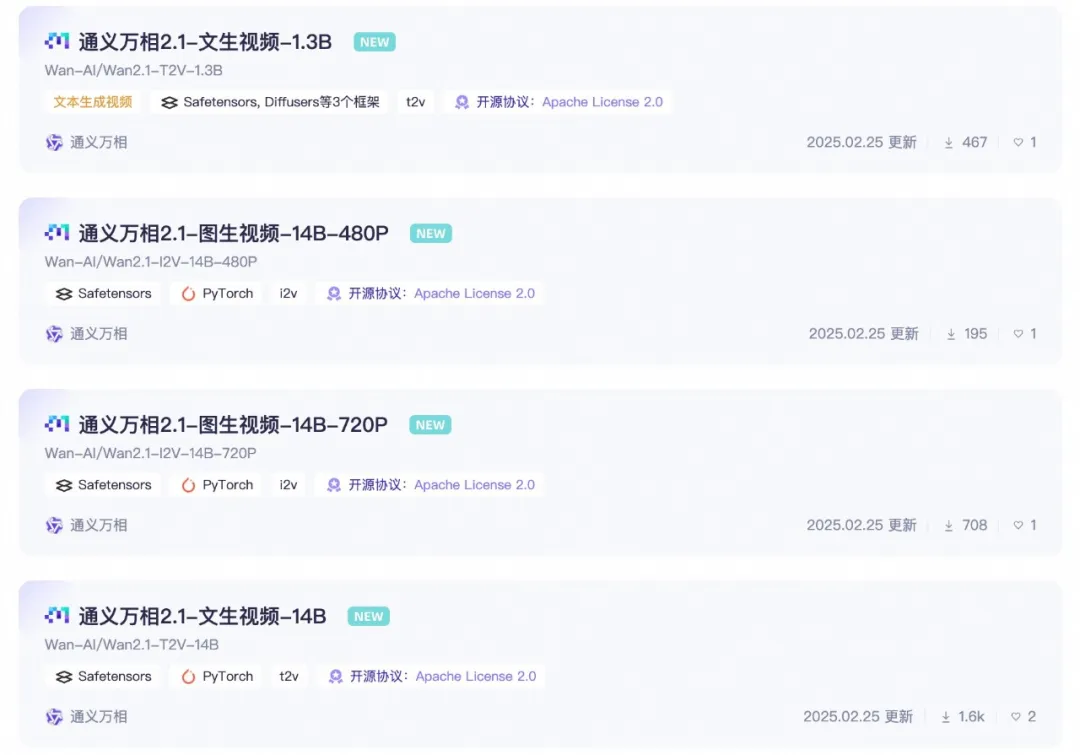
Versioni Open-Source dei Parametri del Modello:
Versione 14B del Modello Wan 2.1
- Prestazioni: Eccelle nel seguire le istruzioni, nella generazione di movimenti complessi, nella modellazione fisica e nella generazione di testo-a-video.
- Benchmark: Ha ottenuto un punteggio totale dell'86.22% nel set di valutazione VBench, superando significativamente altri modelli come Sora, Luma e Pika, e classificandosi al primo posto.
Versione 1.3B del Modello Wan 2.1
- Prestazioni: Supera modelli open-source più grandi e si avvicina ad alcuni modelli closed-source.
- Requisiti Hardware: Può funzionare su GPU consumer con solo 8.2GB di VRAM, in grado di generare video 480P.
- Applicazioni: Adatto per lo sviluppo di modelli secondari e la ricerca accademica.
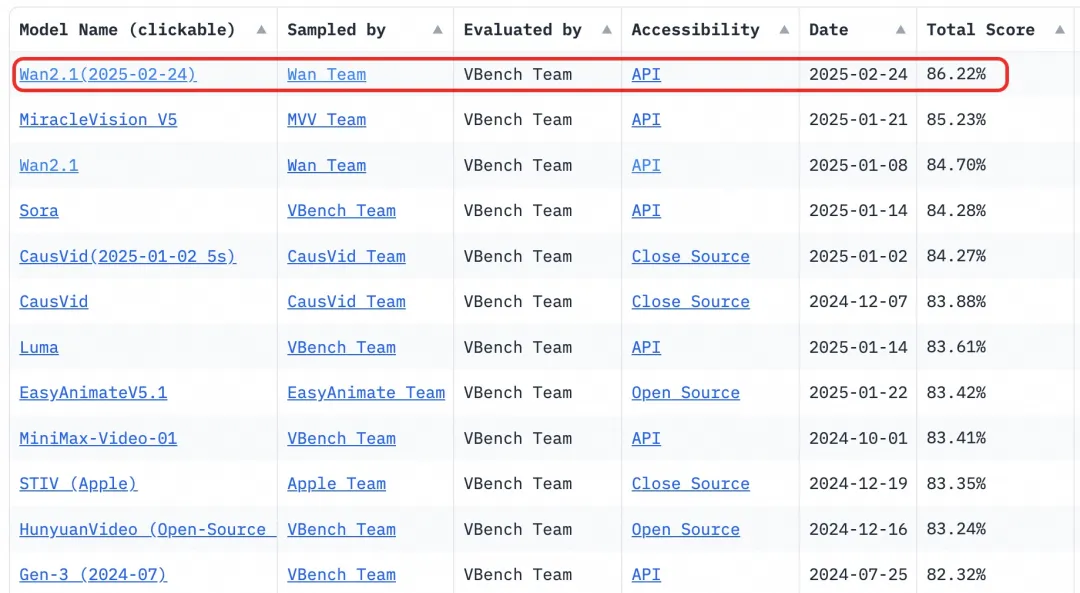
Dal 2023, Alibaba Cloud si è impegnata a rendere open-source i grandi modelli. Il numero di modelli derivati da Qwen ha superato i 100.000, rendendolo la più grande famiglia di modelli AI a livello globale. Con l'open-sourcing di Wan 2.1, Alibaba Cloud ha ora completamente open-sourced i suoi due modelli fondamentali, raggiungendo lo status di open-source per modelli multimodali e su larga scala.
Analisi Tecnica del Modello Wan 2.1 (Wan)
Prestazioni del Modello
Il modello Wan 2.1 supera i modelli open-source esistenti e i migliori modelli closed-source commerciali in vari test di benchmark interni ed esterni. Può dimostrare stabilmente movimenti complessi del corpo umano come rotazioni, salti, giri e rotolamenti, e riprodurre accuratamente scenari fisici complessi del mondo reale come collisioni, rimbalzi e tagli.

In termini di capacità di seguire le istruzioni, il modello può comprendere accuratamente lunghe istruzioni testuali in cinese e inglese, riproducendo fedelmente varie transizioni di scene e interazioni tra personaggi.

Tecnologie Chiave
Basato sui paradigmi mainstream DiT e linear noise schedule Flow Matching, il Wan AI Large Model ha ottenuto progressi significativi nelle capacità generative attraverso una serie di innovazioni tecnologiche. Queste includono lo sviluppo di un efficiente 3D VAE causale, strategie di pre-training scalabili, la costruzione di pipeline di dati su larga scala e l'implementazione di metriche di valutazione automatizzate. Insieme, queste innovazioni hanno migliorato le prestazioni complessive del modello.
Efficiente 3D VAE Causale: Wan AI ha sviluppato una nuova architettura 3D VAE causale specificamente progettata per la generazione video, incorporando varie strategie per migliorare la compressione spaziotemporale, ridurre l'uso della memoria e garantire la causalità temporale.
Video Diffusion Transformer: L'architettura del modello Wan AI è basata sulla struttura mainstream del Video Diffusion Transformer. Assicura una modellazione efficace delle dipendenze spaziotemporali a lungo termine attraverso il meccanismo Full Attention, ottenendo una generazione video temporalmente e spazialmente coerente.
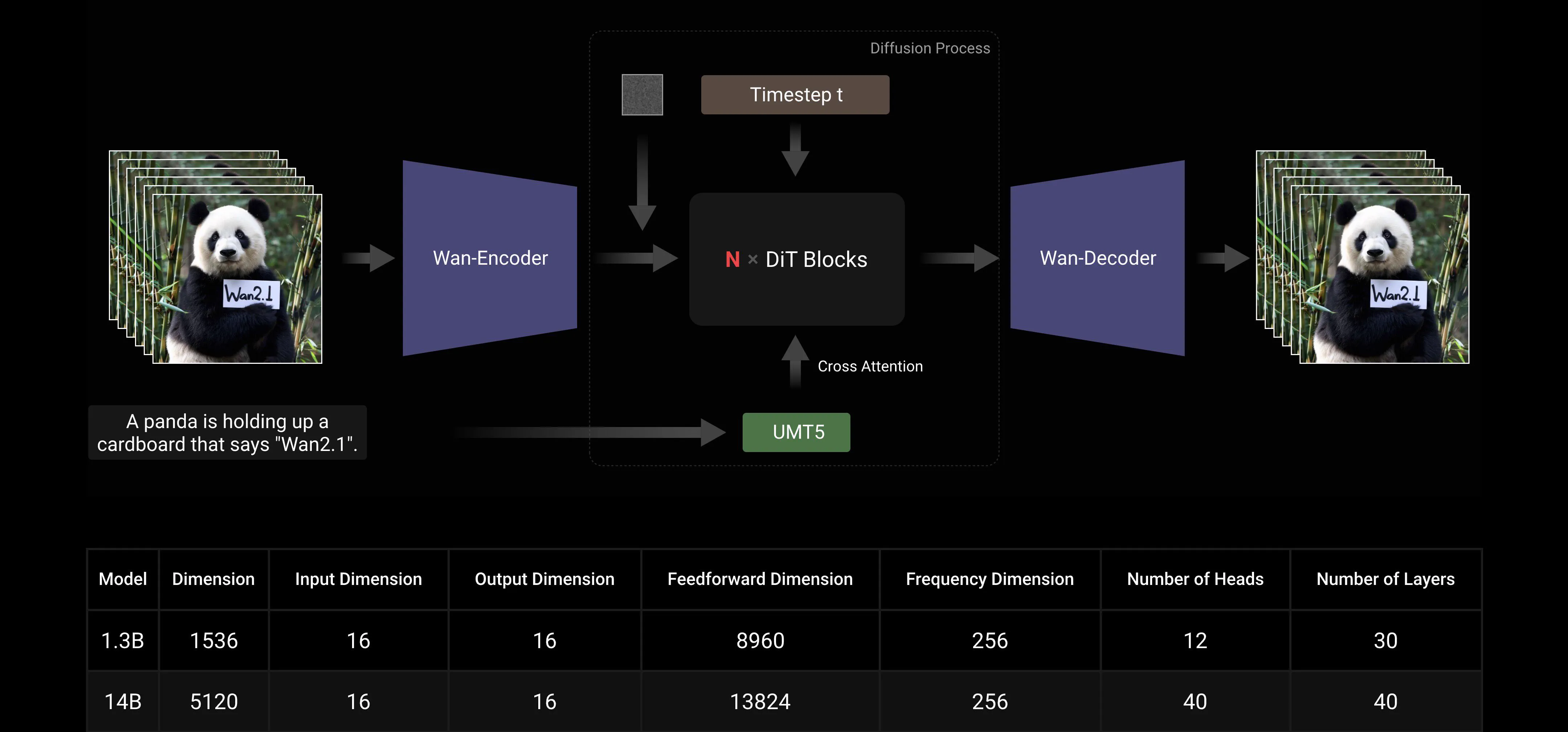
Ottimizzazione dell'Efficienza di Training e Inferenza: Durante la fase di training, per i moduli di codifica del testo e del video, utilizziamo una strategia distribuita che combina Data Parallelism (DP) e Fully Sharded Data Parallelism (FSDP). Per il modulo DiT, adottiamo una strategia parallela ibrida che integra DP, FSDP, RingAttention e Ulysses. Durante la fase di inferenza, per ridurre la latenza della generazione di un singolo video utilizzando più GPU, è necessario selezionare Collective Parallelism (CP) per l'accelerazione distribuita. Inoltre, quando il modello è grande, è anche richiesto il model slicing.

Amichevole verso la Comunità Open-Source
Wan AI ha pienamente supportato più framework mainstream su GitHub e Hugging Face. Supporta già l'esperienza Gradio e l'inferenza accelerata parallela con xDiT. L'integrazione con Diffusers e ComfyUI è anche in rapida implementazione per facilitare la distribuzione dell'inferenza con un clic per gli sviluppatori. Questo non solo abbassa la soglia di sviluppo, ma fornisce anche opzioni flessibili per utenti con diverse esigenze, sia per prototipazione rapida che per distribuzione efficiente in produzione.
Link alla Comunità Open-Source:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Appendice: Dimostrazione del Modello Wan AI
Il primo modello di generazione video che supporta la generazione di testo in cinese e contemporaneamente abilita la generazione di effetti di testo in cinese e inglese:
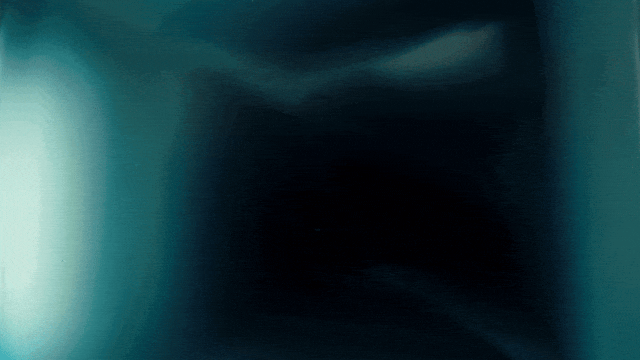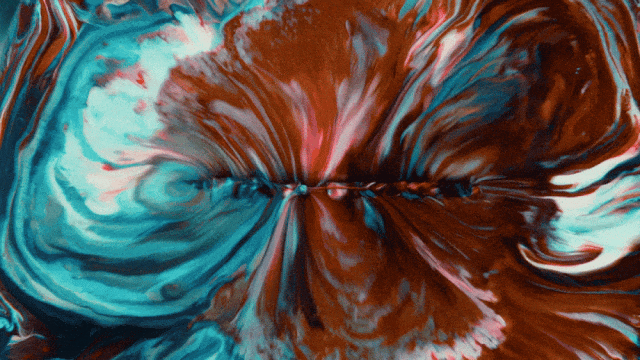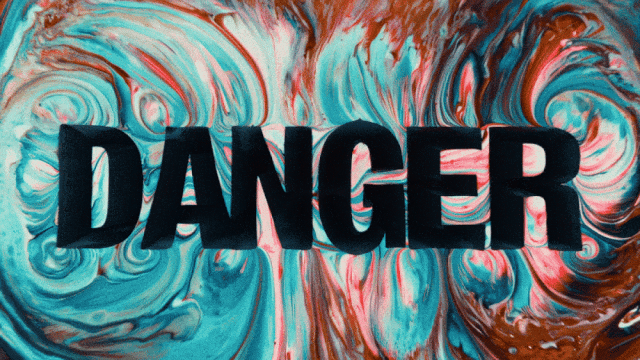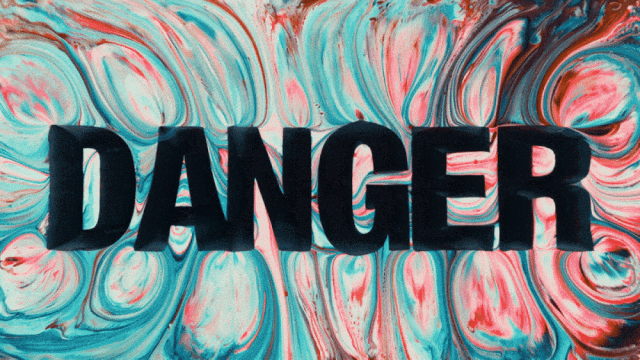
 Capacità di Generazione di Movimenti Più Stabili e Complessi:
Capacità di Generazione di Movimenti Più Stabili e Complessi:

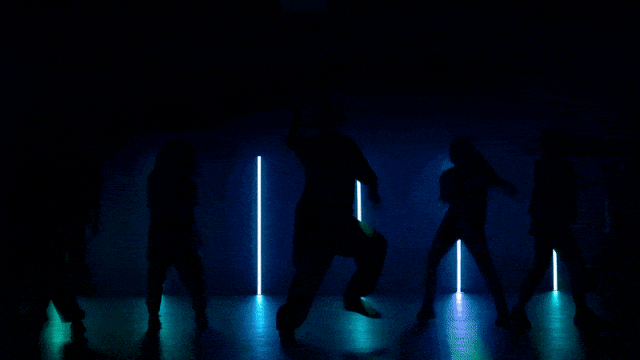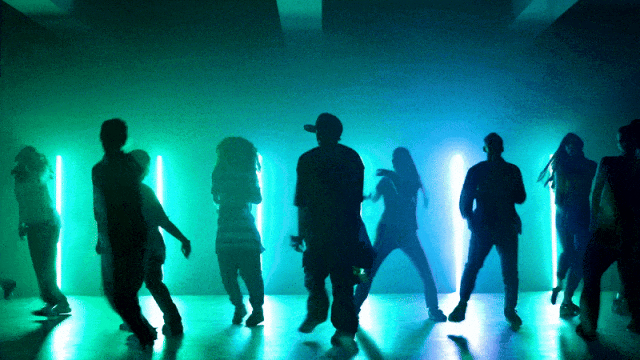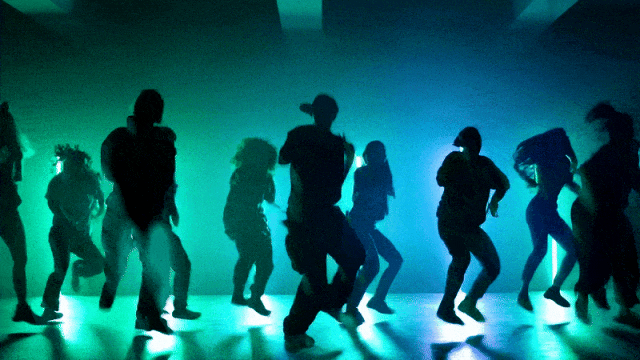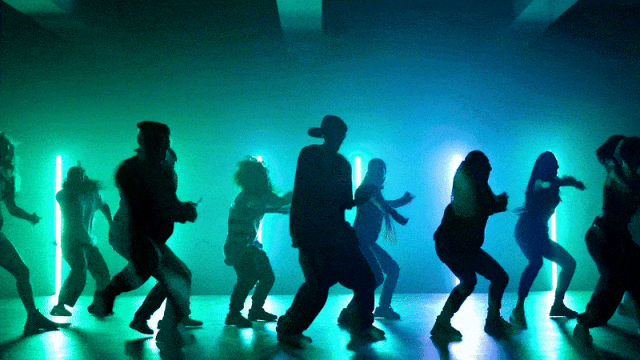 Capacità di Controllo della Fotocamera Più Flessibili::
Capacità di Controllo della Fotocamera Più Flessibili::

 Texture Avanzate, Stili Diversi e Multipli Rapporti d'Aspetto:
Texture Avanzate, Stili Diversi e Multipli Rapporti d'Aspetto:
 Generazione Immagine-a-Video, Rendendo la Creazione Più Controllabile:
Generazione Immagine-a-Video, Rendendo la Creazione Più Controllabile:

