Alibaba Cloud's video generation model, Wan 2.1 (Wan), telah diopen-source di bawah lisensi Apache 2.0. Rilis ini mencakup semua kode inferensi dan bobot untuk versi parameter 14B dan 1.3B, mendukung tugas text-to-video dan image-to-video. Pengembang di seluruh dunia dapat mengakses dan mencoba model ini di GitHub, HuggingFace, dan komunitas Modao.
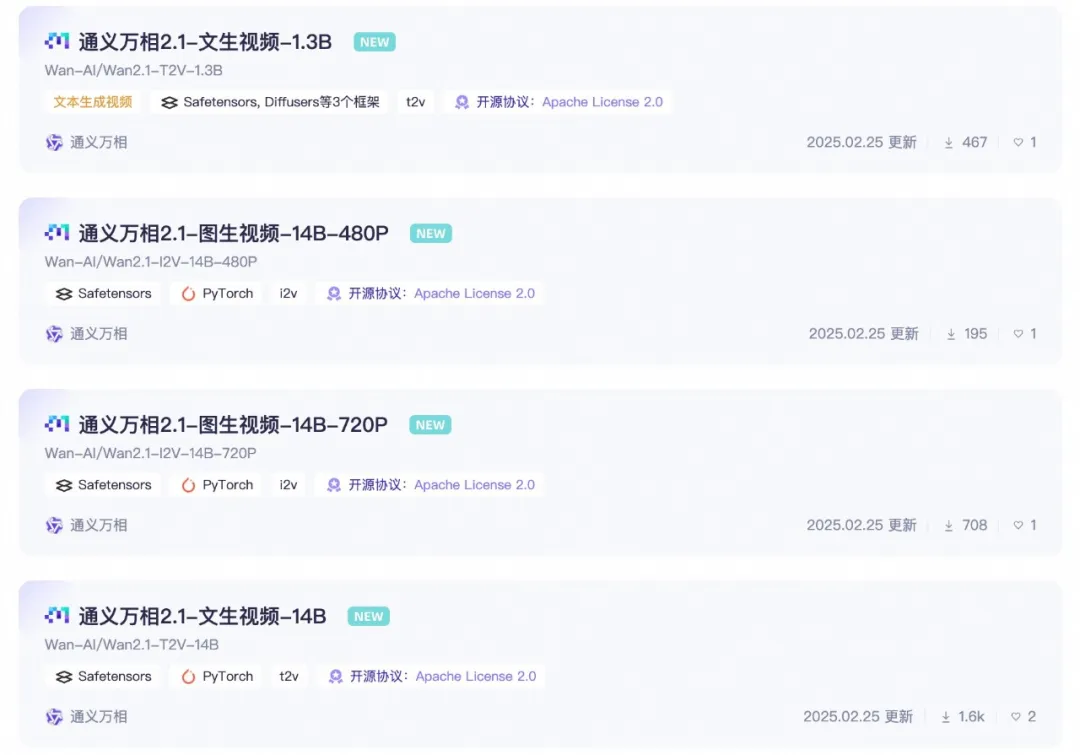
Versi Parameter Model yang Diopen-Source:
Versi 14B dari Model Wan 2.1
- Kinerja: Unggul dalam mengikuti instruksi, menghasilkan gerakan kompleks, pemodelan fisik, dan generasi text-to-video.
- Benchmark: Mencapai skor total 86.22% dalam set evaluasi VBench yang otoritatif, secara signifikan melampaui model lain seperti Sora, Luma, dan Pika, dan menempati peringkat pertama.
Versi 1.3B dari Model Wan 2.1
- Kinerja: Mengungguli model open-source yang lebih besar dan bahkan menyamai beberapa model closed-source.
- Persyaratan Perangkat Keras: Dapat berjalan pada GPU kelas konsumen dengan hanya 8.2GB VRAM, mampu menghasilkan video 480P.
- Aplikasi: Cocok untuk pengembangan model sekunder dan penelitian akademis.
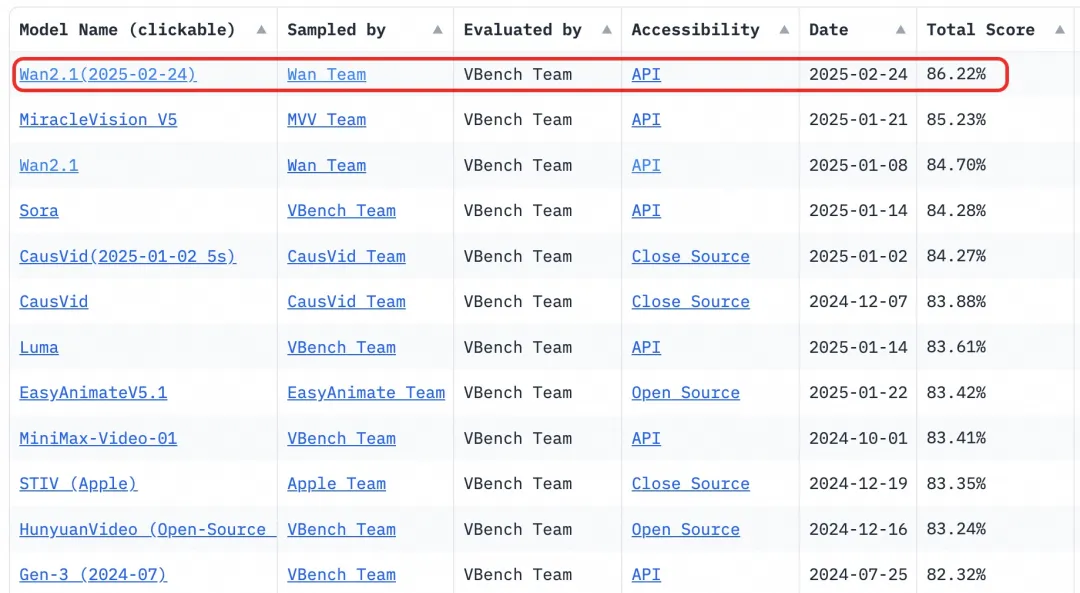
Sejak 2023, Alibaba Cloud telah berkomitmen untuk mengopen-source model besar. Jumlah model turunan dari Qwen telah melampaui 100.000, menjadikannya keluarga model AI terbesar di dunia. Dengan diopen-sourcekannya Wan 2.1, Alibaba Cloud kini telah sepenuhnya mengopen-source dua model dasarnya, mencapai status open-source untuk model besar multimodal dan skala penuh.
Analisis Teknis Model Wan 2.1 (Wan)
Kinerja Model
Model Wan 2.1 mengungguli model open-source yang ada dan model closed-source komersial teratas dalam berbagai tes benchmark internal dan eksternal. Model ini dapat secara stabil menunjukkan gerakan tubuh manusia yang kompleks seperti berputar, melompat, berbalik, dan berguling, serta secara akurat mereproduksi skenario fisik dunia nyata yang kompleks seperti tabrakan, pantulan, dan potongan.

Dalam hal kemampuan mengikuti instruksi, model ini dapat secara akurat memahami instruksi teks panjang dalam bahasa Cina dan Inggris, dengan setia mereproduksi berbagai transisi adegan dan interaksi karakter.

Teknologi Kunci
Berdasarkan paradigma DiT dan jadwal noise linear Flow Matching yang umum, Wan AI Large Model telah mencapai kemajuan signifikan dalam kemampuan generatif melalui serangkaian inovasi teknologi. Ini termasuk pengembangan 3D VAE kausal yang efisien, strategi pra-pelatihan yang dapat diskalakan, pembangunan pipa data skala besar, dan implementasi metrik evaluasi otomatis. Bersama-sama, inovasi ini telah meningkatkan kinerja keseluruhan model.
3D VAE Kausal yang Efisien: Wan AI telah mengembangkan arsitektur 3D VAE kausal baru yang dirancang khusus untuk generasi video, menggabungkan berbagai strategi untuk meningkatkan kompresi spatiotemporal, mengurangi penggunaan memori, dan memastikan kausalitas temporal.
Video Diffusion Transformer: Arsitektur model Wan AI didasarkan pada struktur Video Diffusion Transformer yang umum. Ini memastikan pemodelan yang efektif dari ketergantungan spatiotemporal jangka panjang melalui mekanisme Full Attention, mencapai generasi video yang konsisten secara temporal dan spasial.
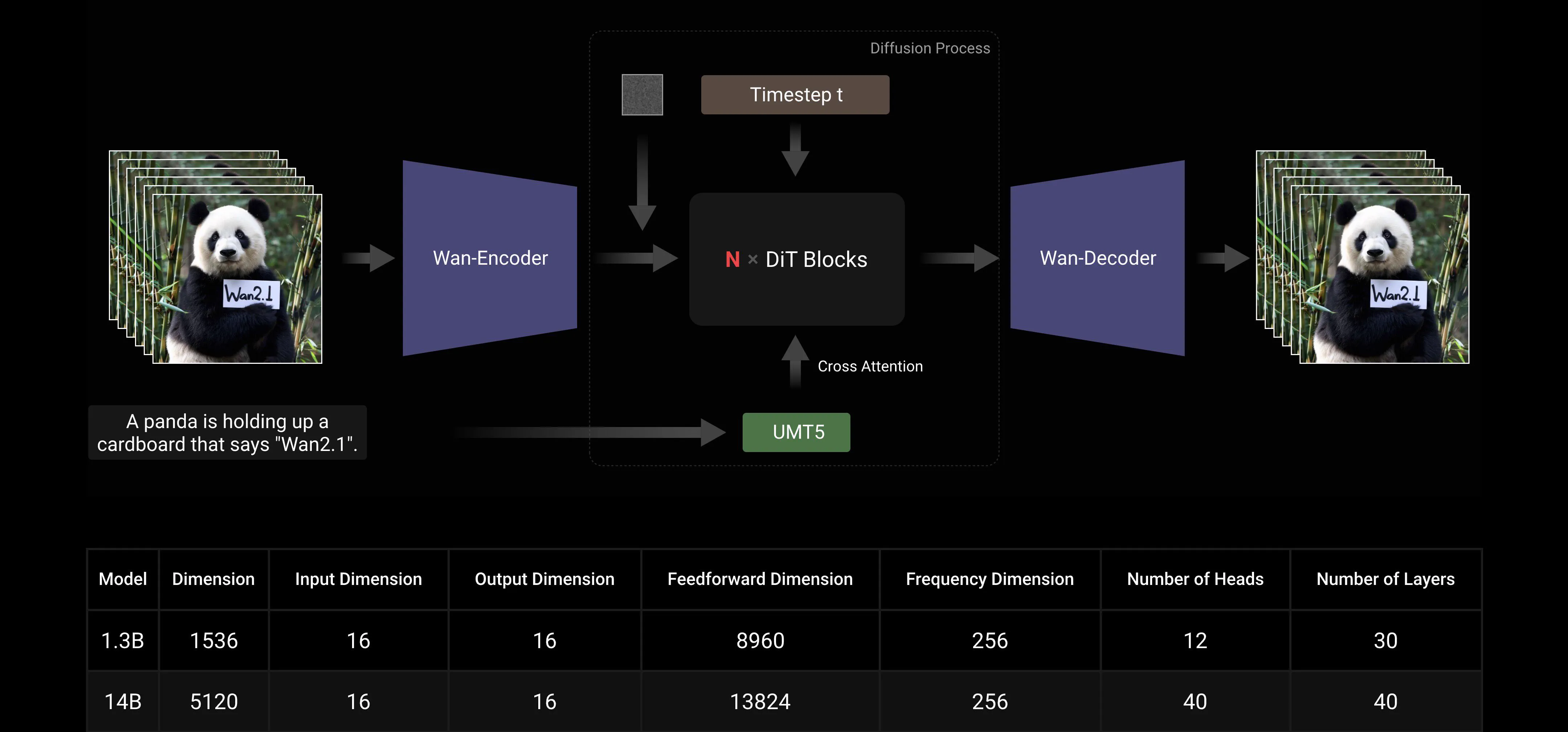
Optimisasi Efisiensi Pelatihan dan Inferensi Model: Selama fase pelatihan, untuk modul pengkodean teks dan video, kami menggunakan strategi terdistribusi yang menggabungkan Data Parallelism (DP) dan Fully Sharded Data Parallelism (FSDP). Untuk modul DiT, kami mengadopsi strategi paralel hybrid yang mengintegrasikan DP, FSDP, RingAttention, dan Ulysses. Selama fase inferensi, untuk mengurangi latensi menghasilkan satu video menggunakan beberapa GPU, kami perlu memilih Collective Parallelism (CP) untuk akselerasi terdistribusi. Selain itu, ketika model besar, pemotongan model juga diperlukan.

Ramah Komunitas Open-Source
Wan AI telah sepenuhnya mendukung beberapa framework utama di GitHub dan Hugging Face. Ini sudah mendukung pengalaman Gradio dan inferensi akselerasi paralel dengan xDiT. Integrasi dengan Diffusers dan ComfyUI juga sedang diimplementasikan dengan cepat untuk memfasilitasi penyebaran inferensi satu klik untuk pengembang. Ini tidak hanya menurunkan ambang pengembangan tetapi juga memberikan opsi fleksibel untuk pengguna dengan kebutuhan berbeda, baik untuk prototipe cepat atau penyebaran produksi yang efisien.
Tautan Komunitas Open-Source:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Lampiran: Demo Model Wan AI
Model generasi video pertama yang mendukung generasi teks dalam bahasa Cina dan secara bersamaan memungkinkan generasi efek teks dalam bahasa Cina dan Inggris:
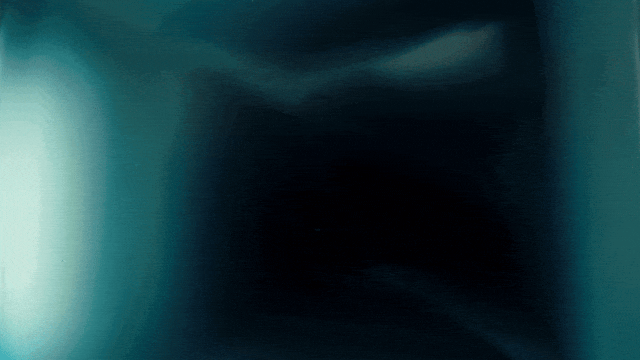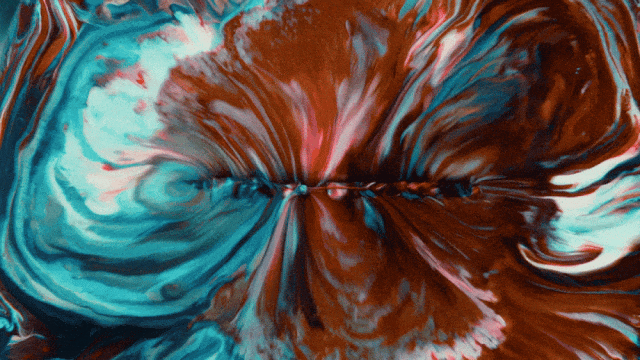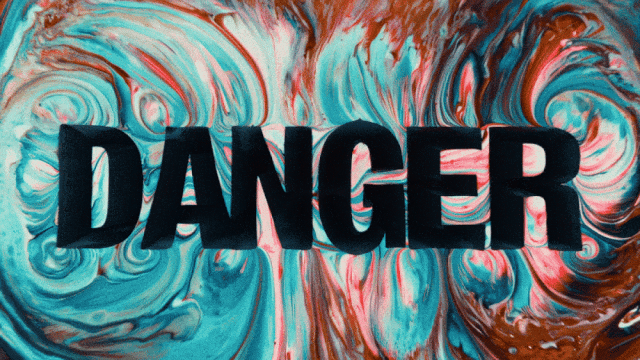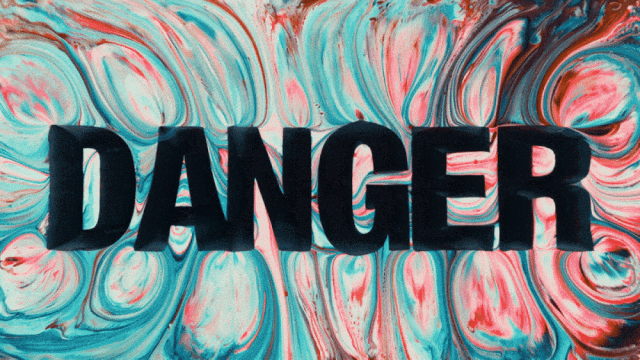
 Kemampuan Generasi Gerakan yang Lebih Stabil dan Kompleks:
Kemampuan Generasi Gerakan yang Lebih Stabil dan Kompleks:

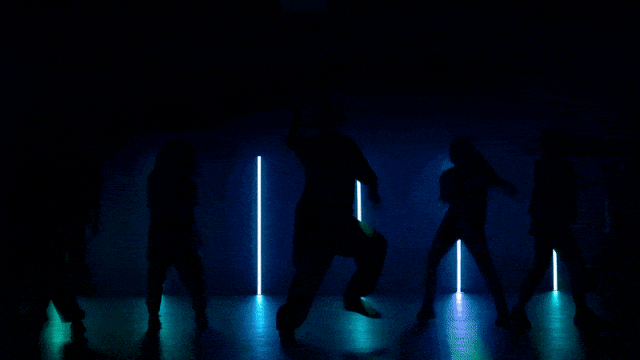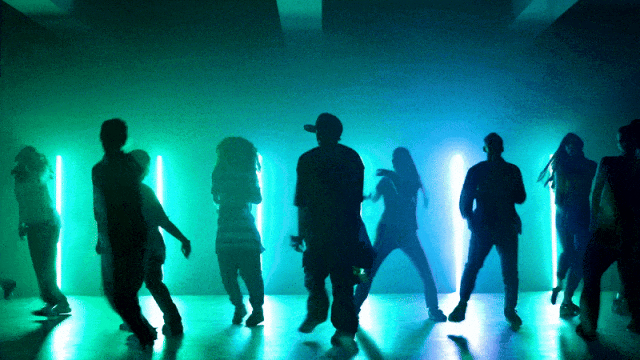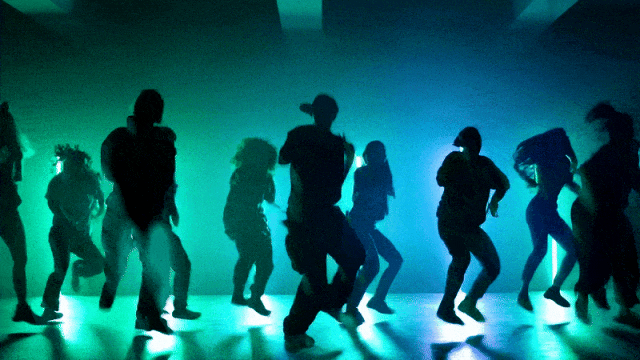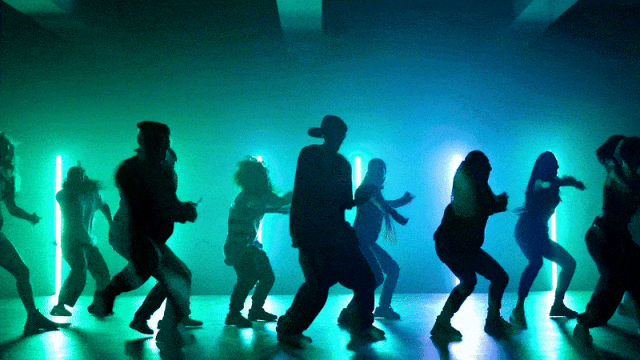 Kemampuan Kontrol Kamera yang Lebih Fleksibel::
Kemampuan Kontrol Kamera yang Lebih Fleksibel::

 Tekstur Lanjutan, Gaya Beragam, dan Beberapa Rasio Aspek:
Tekstur Lanjutan, Gaya Beragam, dan Beberapa Rasio Aspek:
 Generasi Image-to-Video, Membuat Kreasi Lebih Terkendali:
Generasi Image-to-Video, Membuat Kreasi Lebih Terkendali:

