阿里巴巴云的视频生成模型Wan 2.1(Wan)已在Apache 2.0许可下开源。此次发布包括14B和1.3B参数版本的所有推理代码和权重,支持文本到视频和图像到视频任务。全球开发者可以在GitHub、HuggingFace和Modao社区访问和体验该模型。
开源参数版本模型:
Wan 2.1模型的14B版本
- 性能:在指令跟随、复杂运动生成、物理建模和文本到视频生成方面表现出色。
- 基准测试:在权威的VBench评估集中获得86.22%的总分,显著超越Sora、Luma和Pika等其他模型,排名第一。
Wan 2.1模型的1.3B版本
- 性能:优于更大的开源模型,甚至与一些闭源模型相当。
- 硬件要求:可以在仅8.2GB显存的消费级GPU上运行,能够生成480P视频。
- 应用:适合二次模型开发和学术研究。
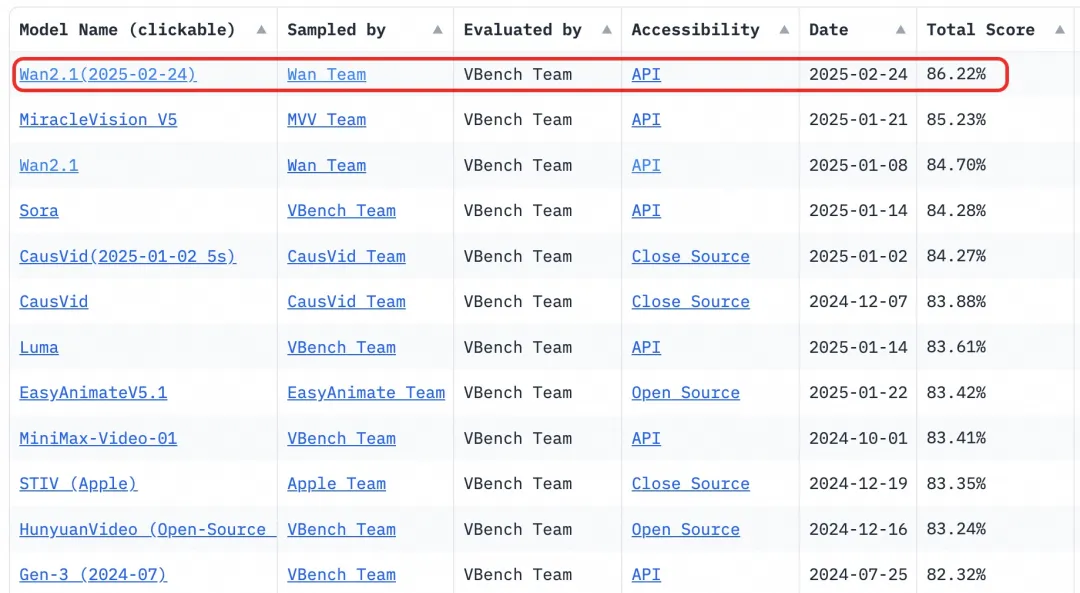
自2023年以来,阿里巴巴云一直致力于开源大模型。Qwen的衍生模型数量已超过10万,成为全球最大的AI模型家族。随着Wan 2.1的开源,阿里巴巴云现已完全开源其两个基础模型,实现了多模态、全规模大模型的开源。
Wan 2.1(Wan)模型技术分析
模型性能
Wan 2.1模型在各种内部和外部基准测试中优于现有的开源模型和顶级商业闭源模型。它能够稳定展示复杂的身体动作,如旋转、跳跃、转身和翻滚,并准确再现复杂的现实物理场景,如碰撞、反弹和切割。

在指令跟随能力方面,该模型能够准确理解中英文长文本指令,忠实再现各种场景转换和角色互动。

关键技术
基于主流的DiT和线性噪声调度Flow Matching范式,Wan AI大模型通过一系列技术创新在生成能力上取得了显著进展。这些创新包括开发高效的因果3D VAE、可扩展的预训练策略、构建大规模数据管道以及实施自动化评估指标。这些创新共同提升了模型的整体性能。
高效因果3D VAE: Wan AI开发了一种专门用于视频生成的新型因果3D VAE架构,结合了多种策略以提高时空压缩、减少内存使用并确保时间因果性。
视频扩散Transformer: Wan AI模型架构基于主流的视频扩散Transformer结构。通过Full Attention机制确保对长期时空依赖的有效建模,实现时空一致的视频生成。
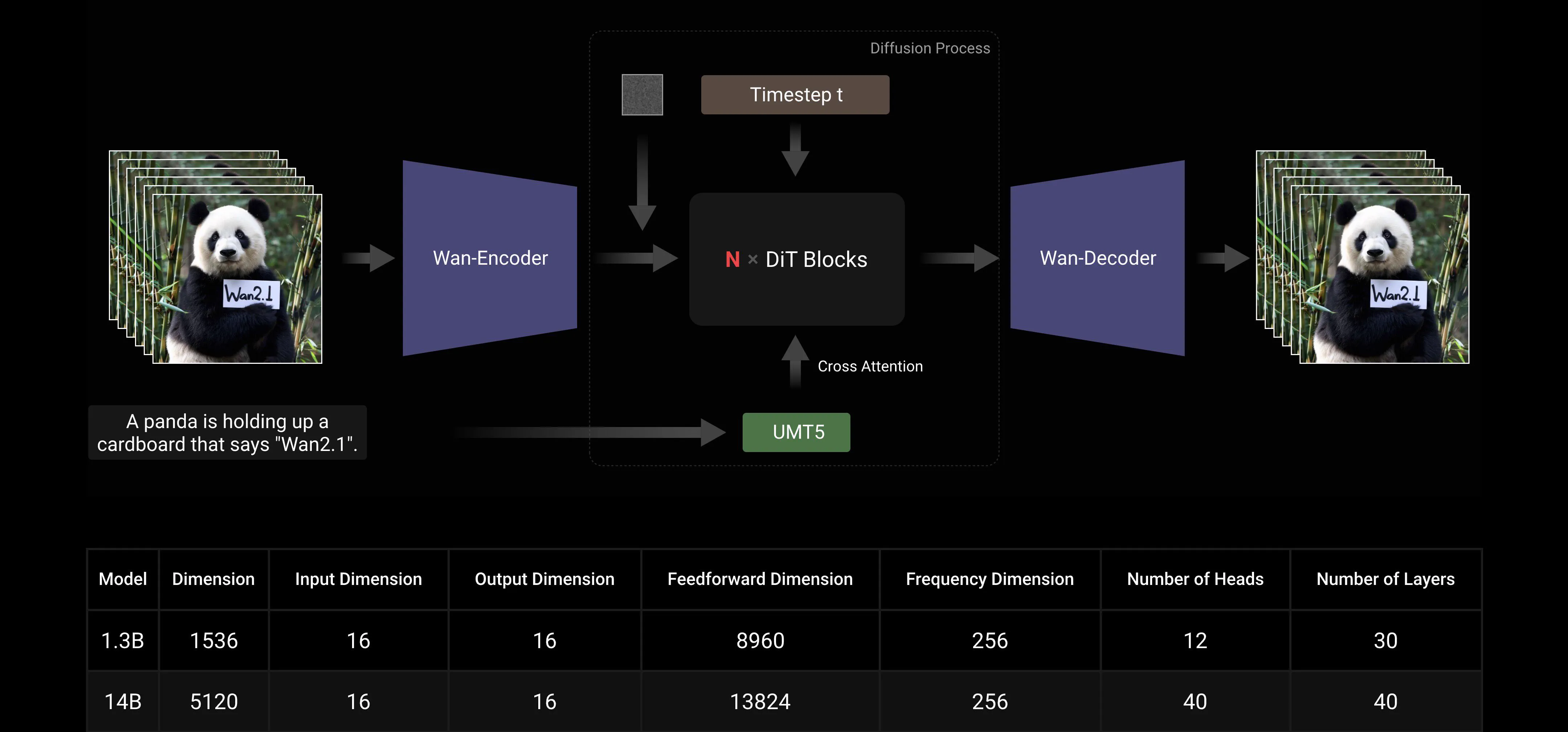
模型训练和推理效率优化: 在训练阶段,对于文本和视频编码模块,我们采用结合数据并行(DP)和完全分片数据并行(FSDP)的分布式策略。对于DiT模块,我们采用结合DP、FSDP、RingAttention和Ulysses的混合并行策略。在推理阶段,为了减少使用多个GPU生成单个视频的延迟,我们需要选择集体并行(CP)进行分布式加速。此外,当模型较大时,还需要进行模型切片。

开源社区友好
Wan AI在GitHub和Hugging Face上全面支持多个主流框架。它已经支持Gradio体验和xDiT的并行加速推理。与Diffusers和ComfyUI的集成也在快速实施,以便开发者一键推理部署。这不仅降低了开发门槛,还为不同需求的用户提供了灵活的选择,无论是快速原型设计还是高效生产部署。
开源社区链接:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
附录:Wan AI模型演示展示
首个支持中文文本生成并同时实现中英文文本效果生成的视频生成模型:
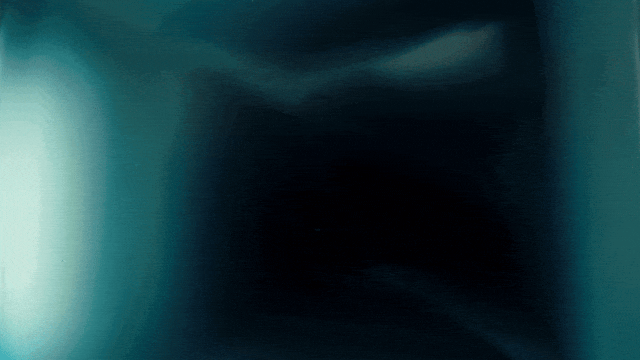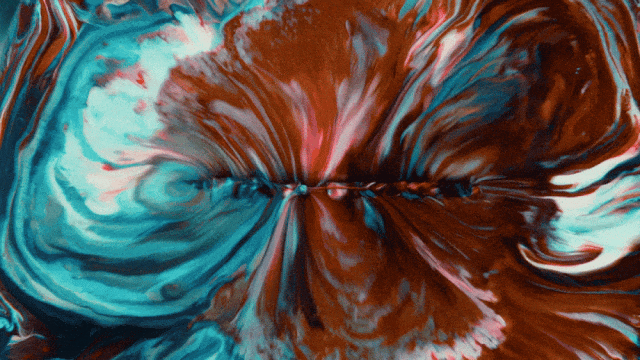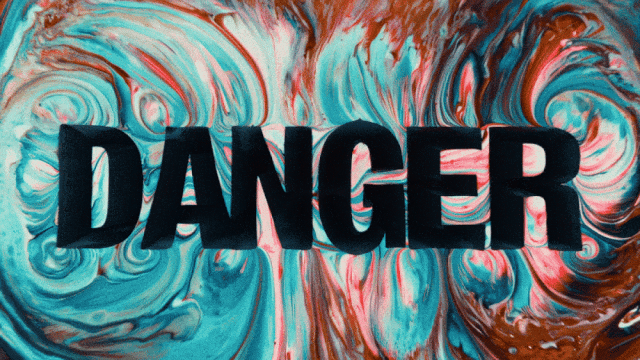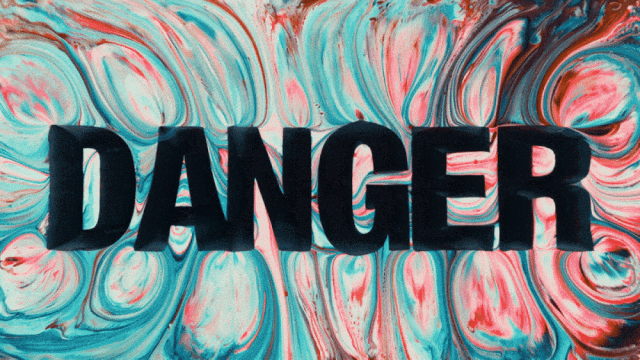
 更稳定和复杂的运动生成能力:
更稳定和复杂的运动生成能力:

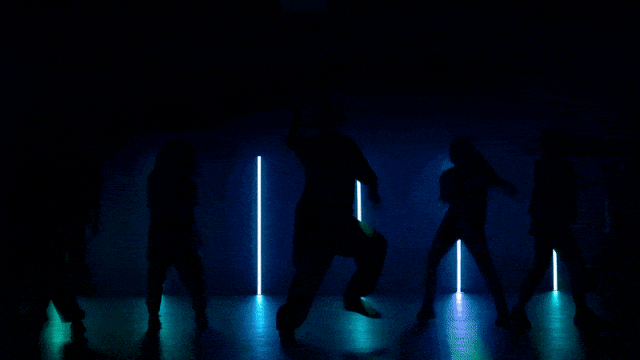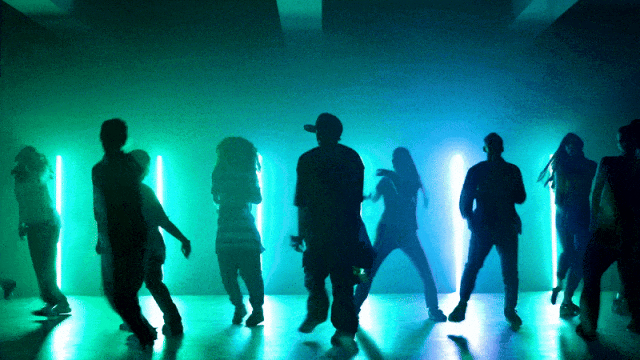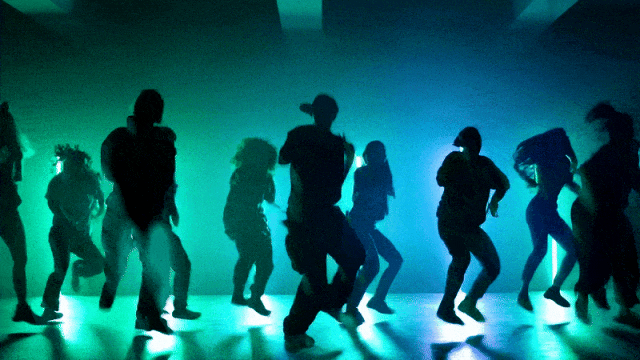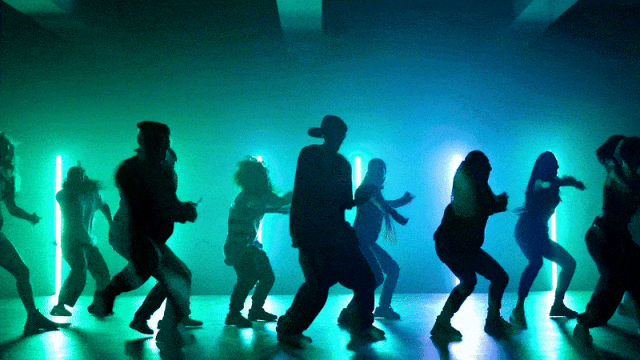 更灵活的相机控制能力:
更灵活的相机控制能力:

 高级纹理、多样风格和多种宽高比:
高级纹理、多样风格和多种宽高比:

 图像到视频生成,使创作更可控:
图像到视频生成,使创作更可控:

