Модель генерации видео Alibaba Cloud, Wan 2.1 (Wan), была открыта под лицензией Apache 2.0. Этот релиз включает весь код для вывода и веса для версий с 14B и 1.3B параметрами, поддерживая задачи как text-to-video, так и image-to-video. Разработчики по всему миру могут получить доступ и испытать модель на GitHub, HuggingFace и сообществе Modao.
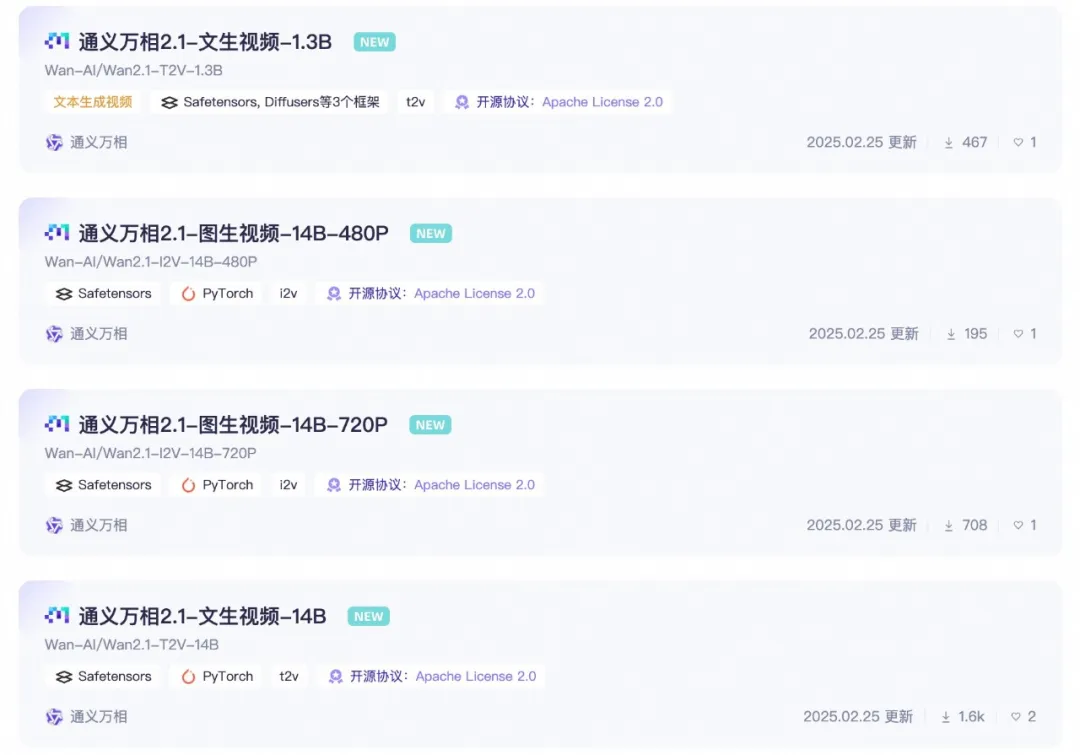
Открытые версии параметров модели:
14B версия модели Wan 2.1
- Производительность: Превосходит в следовании инструкциям, генерации сложных движений, физическом моделировании и генерации видео из текста.
- Бенчмарк: Достиг общего балла 86.22% в авторитетном наборе оценок VBench, значительно превосходя другие модели, такие как Sora, Luma и Pika, и занимая первое место.
1.3B версия модели Wan 2.1
- Производительность: Превосходит более крупные открытые модели и даже соответствует некоторым закрытым моделям.
- Требования к оборудованию: Может работать на потребительских GPU с всего 8.2GB видеопамяти, способна генерировать видео 480P.
- Применения: Подходит для разработки вторичных моделей и академических исследований.
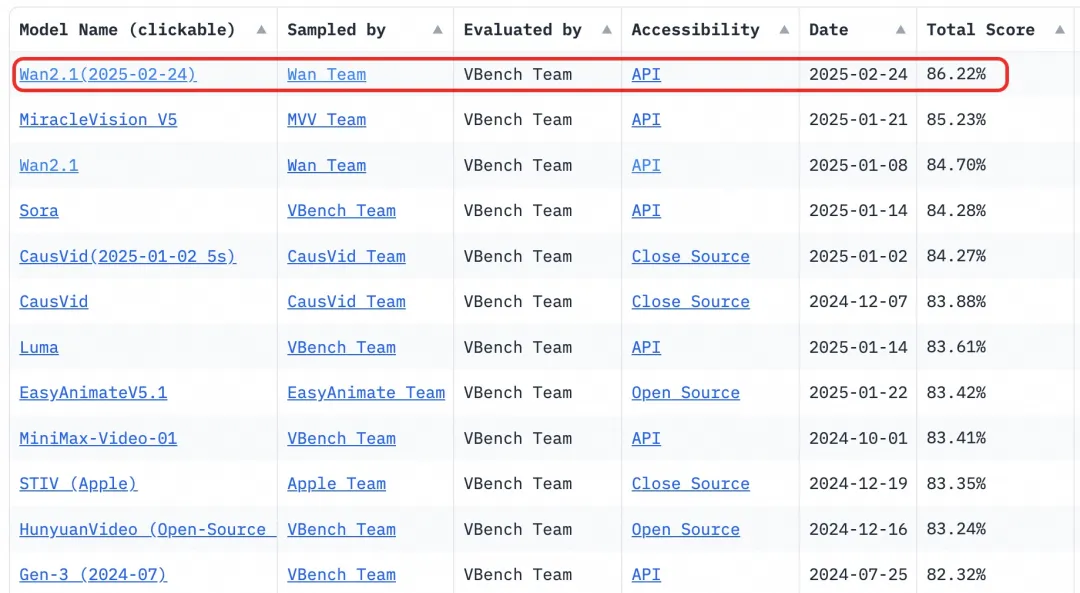
С 2023 года Alibaba Cloud стремится к открытию больших моделей. Количество производных моделей от Qwen превысило 100,000, что делает его крупнейшим семейством моделей ИИ в мире. С открытием Wan 2.1, Alibaba Cloud теперь полностью открыла свои две основные модели, достигнув статуса открытого исходного кода для мультимодальных, полномасштабных больших моделей.
Технический анализ модели Wan 2.1 (Wan)
Производительность модели
Модель Wan 2.1 превосходит существующие открытые модели и ведущие коммерческие закрытые модели в различных внутренних и внешних тестах. Она может стабильно демонстрировать сложные движения человеческого тела, такие как вращение, прыжки, повороты и кувырки, и точно воспроизводить сложные физические сценарии реального мира, такие как столкновения, отскоки и разрезы.

В плане способности следовать инструкциям, модель может точно понимать длинные текстовые инструкции на китайском и английском языках, верно воспроизводя различные переходы сцен и взаимодействия персонажей.

Ключевые технологии
Основываясь на основных парадигмах DiT и линейного расписания шума Flow Matching, Wan AI Large Model достиг значительного прогресса в генеративных способностях через ряд технологических инноваций. Эти инновации включают разработку эффективного причинного 3D VAE, масштабируемых стратегий предварительного обучения, создание крупномасштабных конвейеров данных и реализацию автоматизированных метрик оценки. Вместе эти инновации повысили общую производительность модели.
Эффективный причинный 3D VAE: Wan AI разработал новую архитектуру причинного 3D VAE, специально предназначенную для генерации видео, включая различные стратегии для улучшения пространственно-временного сжатия, уменьшения использования памяти и обеспечения временной причинности.
Видео диффузионный трансформер: Архитектура модели Wan AI основана на основной структуре Video Diffusion Transformer. Она обеспечивает эффективное моделирование долгосрочных пространственно-временных зависимостей через механизм Full Attention, достигая временно и пространственно согласованной генерации видео.
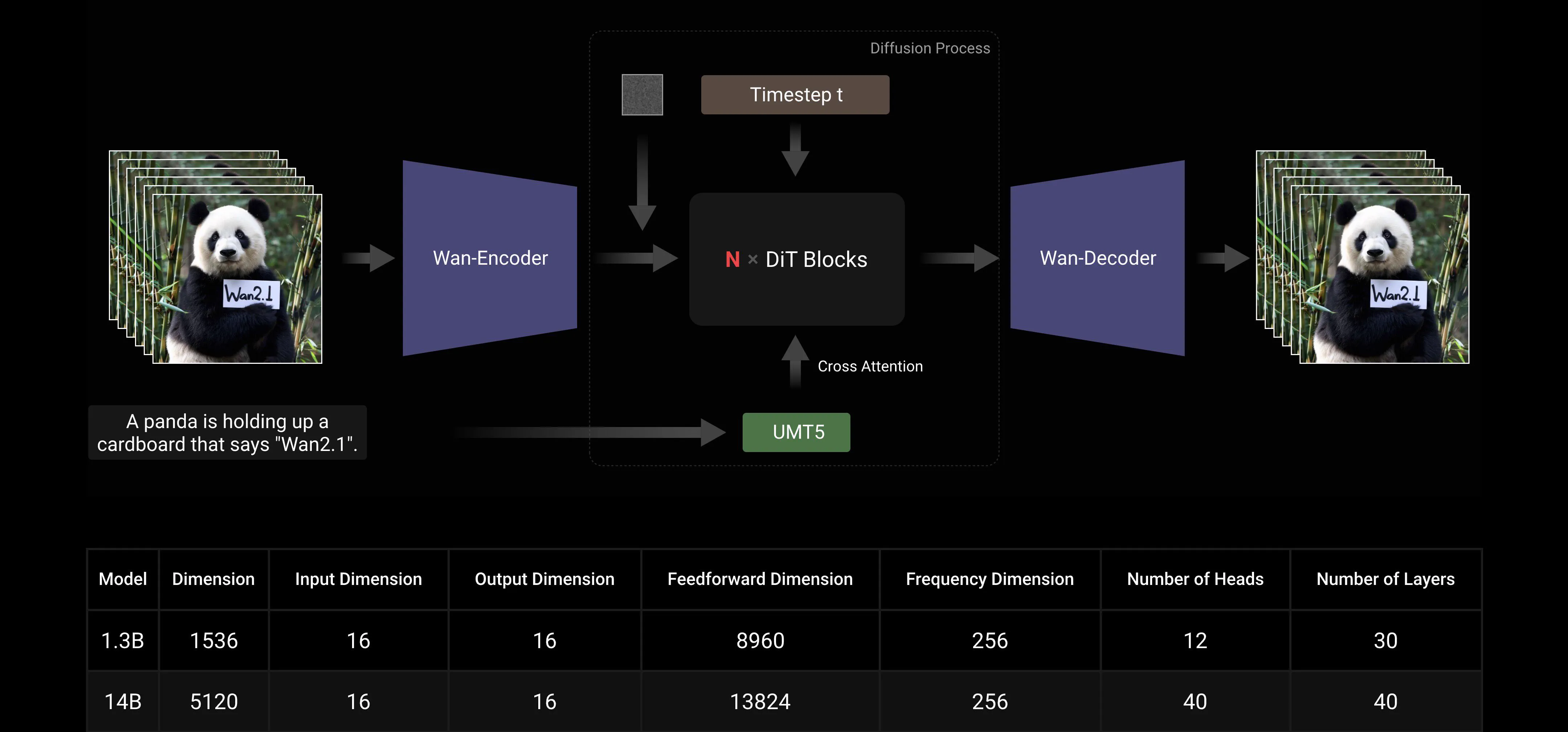
Оптимизация эффективности обучения и вывода модели: На этапе обучения, для модулей кодирования текста и видео, мы используем распределенную стратегию, сочетающую Data Parallelism (DP) и Fully Sharded Data Parallelism (FSDP). Для модуля DiT мы применяем гибридную параллельную стратегию, которая интегрирует DP, FSDP, RingAttention и Ulysses. На этапе вывода, чтобы уменьшить задержку генерации одного видео с использованием нескольких GPU, нам нужно выбрать Collective Parallelism (CP) для распределенного ускорения. Кроме того, когда модель большая, также требуется нарезка модели.

Дружелюбие к открытому сообществу
Wan AI полностью поддерживает несколько основных фреймворков на GitHub и Hugging Face. Она уже поддерживает опыт Gradio и параллельное ускоренное вывод с xDiT. Интеграция с Diffusers и ComfyUI также быстро реализуется, чтобы облегчить разработчикам однокликовое развертывание вывода. Это не только снижает порог разработки, но и предоставляет гибкие варианты для пользователей с разными потребностями, будь то быстрое прототипирование или эффективное производственное развертывание.
Ссылки на открытое сообщество:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Приложение: Демонстрация модели Wan AI
Первая модель генерации видео, которая поддерживает генерацию текста на китайском и одновременно позволяет генерировать текстовые эффекты на китайском и английском языках:
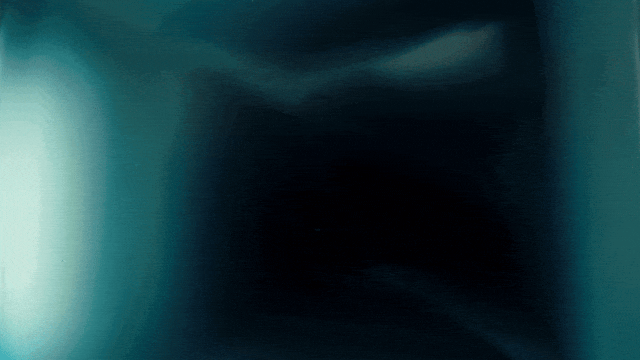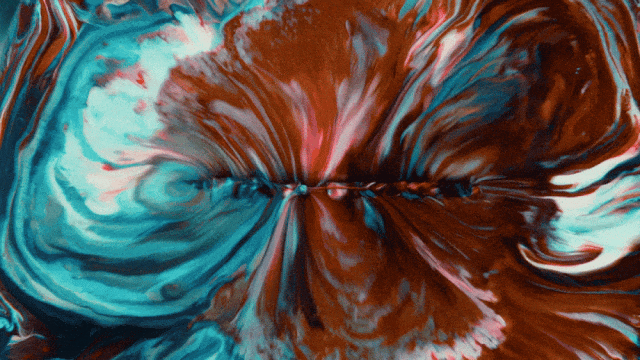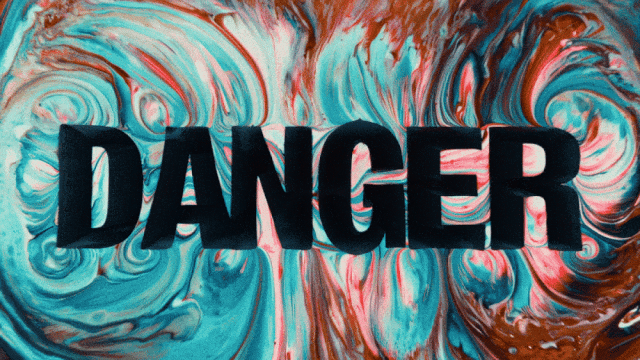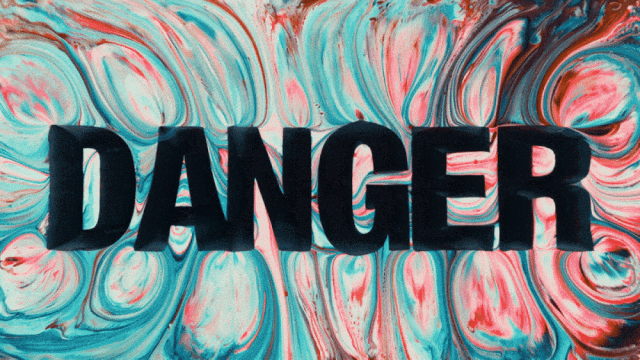
 Более стабильные и сложные возможности генерации движений:
Более стабильные и сложные возможности генерации движений:

 Более гибкие возможности управления камерой::
Более гибкие возможности управления камерой::

 Продвинутая текстура, разнообразные стили и несколько соотношений сторон:
Продвинутая текстура, разнообразные стили и несколько соотношений сторон:
 Генерация видео из изображений, делая создание более контролируемым:
Генерация видео из изображений, делая создание более контролируемым:

