Alibaba Cloudのビデオ生成モデル、Wan 2.1(Wan)は、Apache 2.0ライセンスの下でオープンソース化されました。このリリースには、14Bと1.3Bのパラメータバージョンのすべての推論コードと重みが含まれており、テキストからビデオ、画像からビデオのタスクをサポートしています。世界中の開発者は、GitHub、HuggingFace、Modaoコミュニティでモデルにアクセスし、体験することができます。
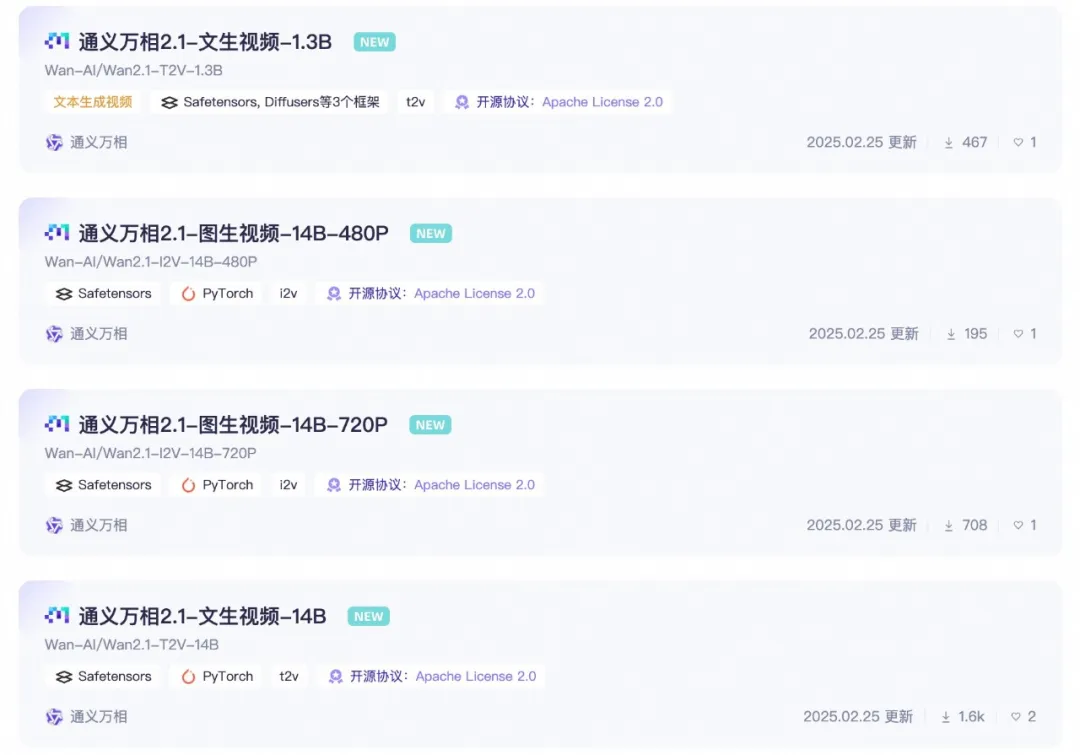
モデルのオープンソース化されたパラメータバージョン:
Wan 2.1モデルの14Bバージョン
- 性能: 指示の追従、複雑なモーション生成、物理モデリング、テキストからビデオ生成に優れています。
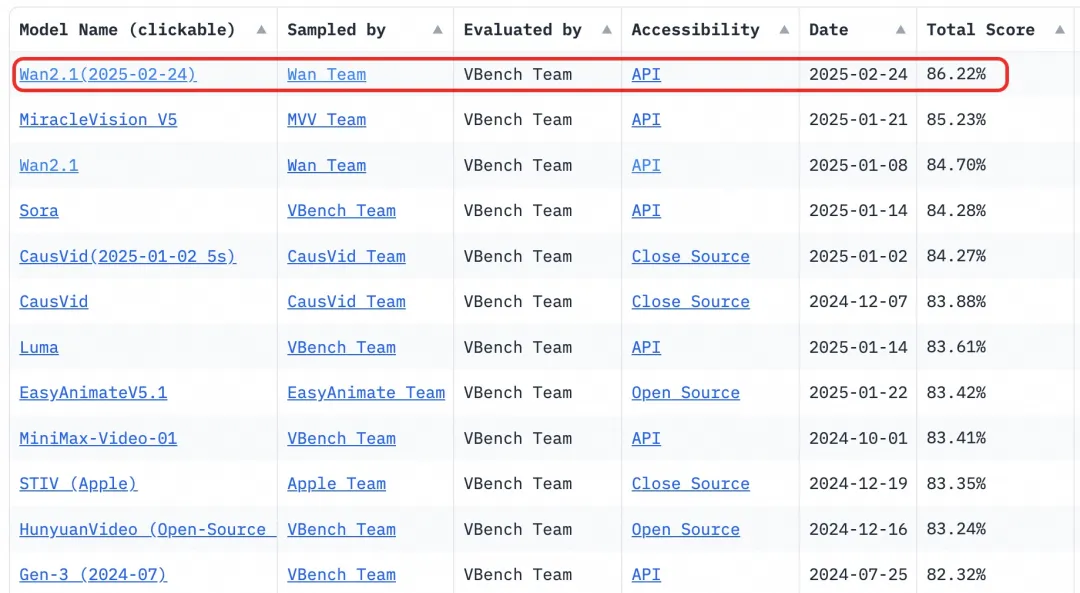
- ベンチマーク: 権威あるVBench評価セットで86.22%の総合スコアを達成し、Sora、Luma、Pikaなどの他のモデルを大幅に上回り、1位を獲得しました。
Wan 2.1モデルの1.3Bバージョン
- 性能: より大きなオープンソースモデルを上回り、一部のクローズドソースモデルにも匹敵します。
- ハードウェア要件: 8.2GBのVRAMを搭載したコンシューマーグレードのGPUで動作可能で、480Pのビデオを生成できます。
- アプリケーション: 二次モデル開発や学術研究に適しています。
2023年以来、Alibaba Cloudは大規模モデルのオープンソース化に取り組んでいます。Qwenから派生したモデルの数は10万を超え、世界最大のAIモデルファミリーとなっています。Wan 2.1のオープンソース化により、Alibaba Cloudは2つの基盤モデルを完全にオープンソース化し、マルチモーダル、フルスケールの大規模モデルのオープンソース化を達成しました。
Wan 2.1(Wan)モデルの技術分析
モデル性能
Wan 2.1モデルは、既存のオープンソースモデルやトップクラスの商用クローズドソースモデルをさまざまな内部および外部のベンチマークテストで上回ります。回転、ジャンプ、ターン、ローリングなどの複雑な人体の動きを安定して示し、衝突、反発、切断などの複雑な現実世界の物理シナリオを正確に再現できます。

指示追従能力において、モデルは中国語と英語の長いテキスト指示を正確に理解し、さまざまなシーンの遷移やキャラクターのインタラクションを忠実に再現します。

主要技術
主流のDiTと線形ノイズスケジュールFlow Matchingパラダイムに基づき、Wan AI大規模モデルは、効率的な因果3D VAEの開発、スケーラブルな事前学習戦略、大規模データパイプラインの構築、自動評価指標の実装など、一連の技術革新を通じて生成能力の大幅な進歩を達成しました。これらの革新がモデルの全体的な性能を向上させました。
効率的な因果3D VAE: Wan AIは、ビデオ生成に特化した新しい因果3D VAEアーキテクチャを開発し、時空間圧縮の改善、メモリ使用量の削減、時間的因果性の確保を図るさまざまな戦略を組み込みました。
ビデオ拡散トランスフォーマー: Wan AIモデルアーキテクチャは、主流のビデオ拡散トランスフォーマー構造に基づいています。Full Attentionメカニズムを通じて長期的な時空間依存関係の効果的なモデリングを確保し、時間的および空間的に一貫したビデオ生成を実現します。
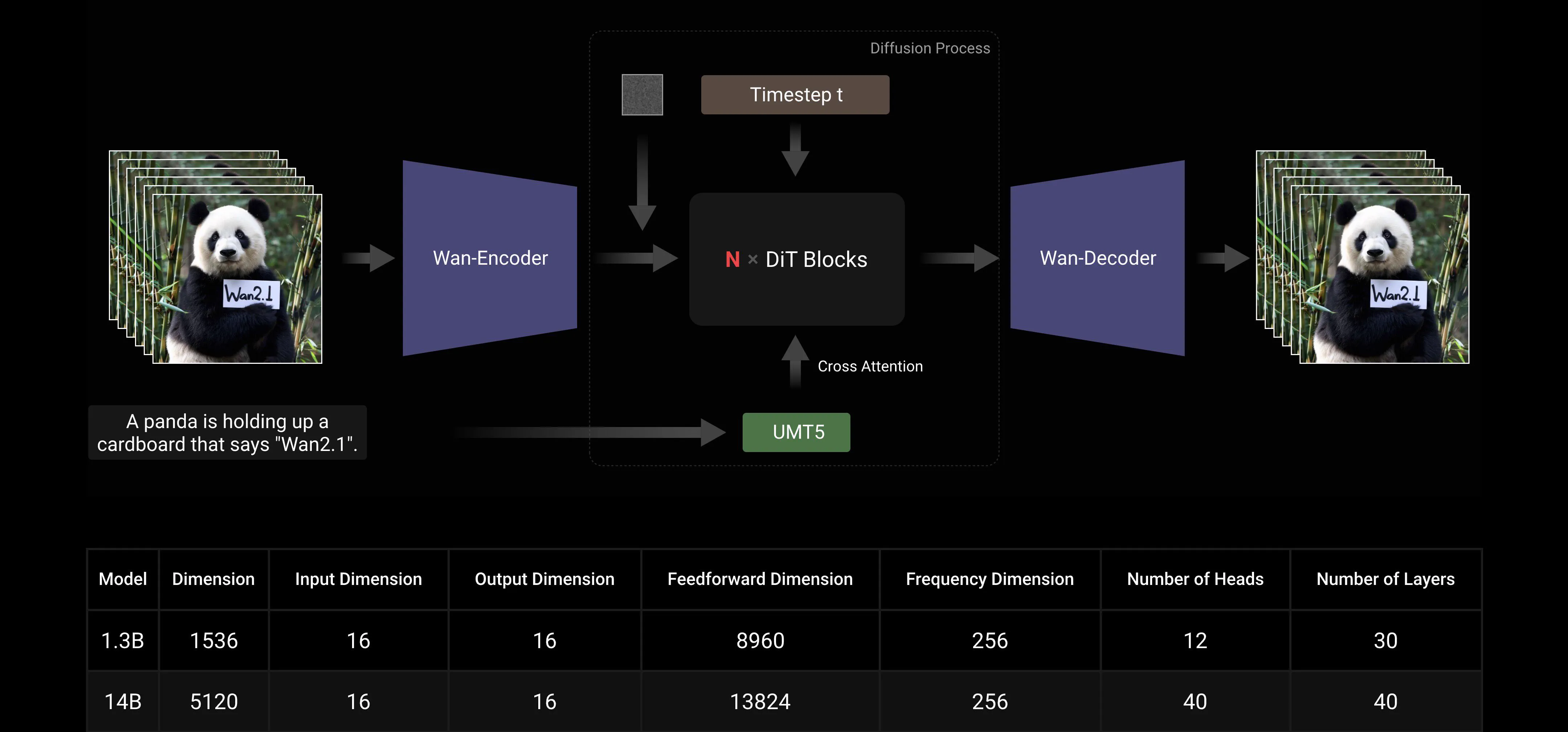
モデルトレーニングと推論効率の最適化: トレーニングフェーズでは、テキストとビデオエンコーディングモジュールに対して、Data Parallelism(DP)とFully Sharded Data Parallelism(FSDP)を組み合わせた分散戦略を採用します。DiTモジュールに対しては、DP、FSDP、RingAttention、Ulyssesを統合したハイブリッド並列戦略を採用します。推論フェーズでは、複数のGPUを使用して単一のビデオを生成する際の遅延を減らすために、Collective Parallelism(CP)を選択して分散加速を行います。また、モデルが大きい場合、モデルスライシングも必要です。

オープンソースコミュニティフレンドリー
Wan AIは、GitHubとHugging Faceで複数の主流フレームワークを完全にサポートしています。すでにGradio体験とxDiTによる並列加速推論をサポートしており、DiffusersとComfyUIとの統合も迅速に進められており、開発者がワンクリックで推論をデプロイできるようにしています。これにより、開発のハードルが下がり、迅速なプロトタイピングや効率的な生産デプロイメントなど、さまざまなニーズを持つユーザーに柔軟な選択肢を提供します。
オープンソースコミュニティリンク:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
付録: Wan AIモデルデモ展示
中国語テキスト生成をサポートし、同時に中国語と英語のテキストエフェクト生成を可能にする最初のビデオ生成モデル:
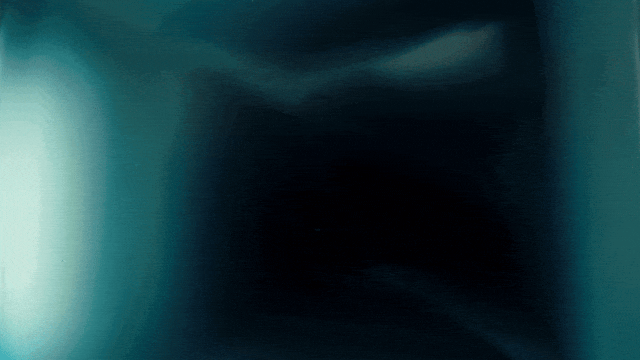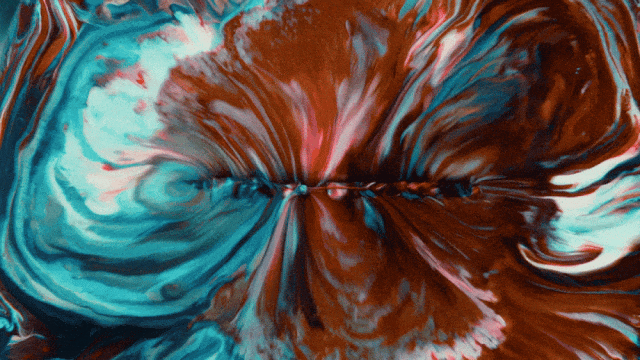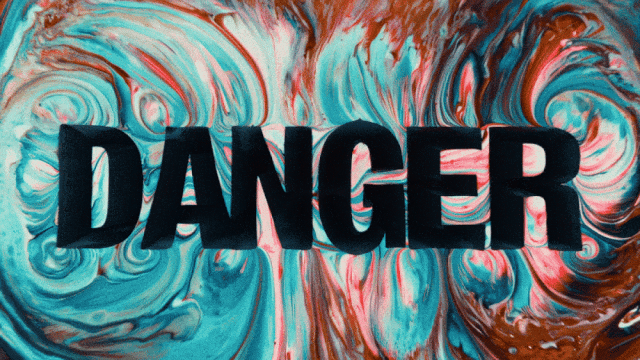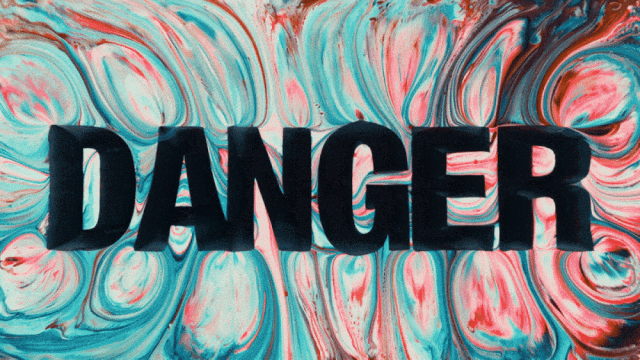
 より安定した複雑なモーション生成能力:
より安定した複雑なモーション生成能力:

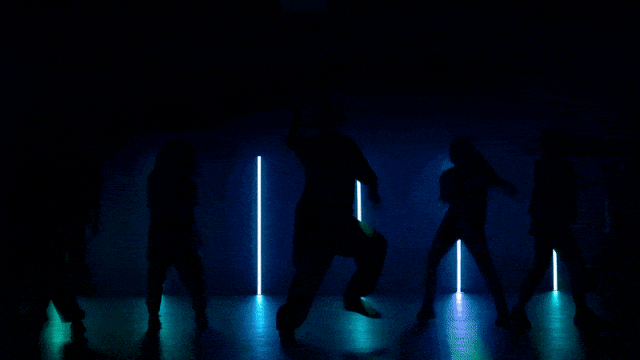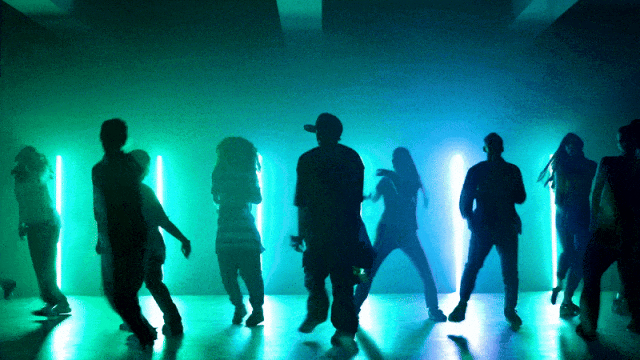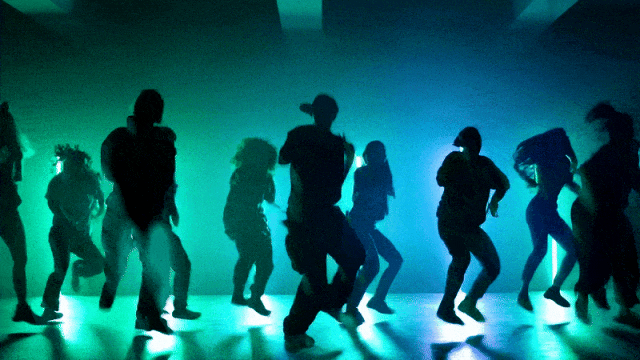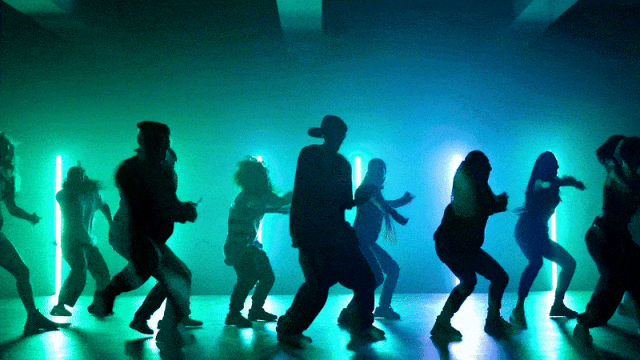 より柔軟なカメラ制御能力::
より柔軟なカメラ制御能力::

 高度なテクスチャ、多様なスタイル、複数のアスペクト比:
高度なテクスチャ、多様なスタイル、複数のアスペクト比:
 画像からビデオ生成、創作をよりコントロール可能に:
画像からビデオ生成、創作をよりコントロール可能に:

