技術レポート
詳細な技術報告書の発表をお楽しみに。
主流の拡散トランスフォーマーパラダイムに基づき、Wan 2.1は一連の革新により生成能力を大幅に向上させました。新しい時空変分オートエンコーダ(VAE)、スケーラブルなプレトレーニング戦略、大規模データ構築、自動化評価指標などの貢献により、モデルのパフォーマンスと多様性が向上しました。
3D変分オートエンコーダ
ビデオ生成のために設計された新しい3D因果VAEアーキテクチャを提案しています。複数の戦略を組み合わせて、時空圧縮を改善し、メモリ使用量を減らし、時間的因果関係を確保します。これらの強化により、VAEはより効率的でスケーラブルになり、拡散型生成モデル(DiTなど)との統合に適しています。
任意の長さのビデオのエンコードとデコードを効率的にサポートするために、3D VAEの因果畳み込みモジュールに特徴キャッシュメカニズムを実装しました。具体的には、ビデオシーケンスフレームの数は1 + Tの入力形式に従います。したがって、ビデオを1 + T/4のチャンクに分割し、チャンクの数は潜在特徴の数と一致します。入力ビデオシーケンスを処理する際に、モデルはチャンクごとのエンコードとデコード操作を行います。時間圧縮比に基づき、各処理チャンクのフレーム数は最大4フレームに制限され、これによりGPUメモリのオーバーフローを防ぎます。
実験結果は、ビデオVAEが両方の指標で非常に競争力があることを示しており、優れたビデオ品質と高い処理効率の両方を示しています。注目に値するのは、同じハードウェア環境(つまり、単一のA800 GPU)で、現在のSOTA方法(つまり、HunYuanVideo)よりも再構築速度が2.5倍高いことです。この速度の利点は、VAEモデルの小さな設計と特徴キャッシュメカニズムにより、より高い解像度でさらに顕著になります。
ビデオ拡散DiT
Wan AI 2.1は、主流の拡散トランスフォーマーパラダイム内でフローマッチングフレームワークを使用して設計されています。モデルアーキテクチャでは、T5エンコーダーを使用して入力の多言語テキストをエンコードし、各トランスフォーマーブロック内でクロスアテンションを使用してテキストをモデル構造に埋め込みます。さらに、入力の時間埋め込みを処理し、6つの調整パラメータを個別に予測するために、線形層とSiLU層を使用します。このMLPはすべてのトランスフォーマーブロックで共有され、各ブロックが異なるバイアスを学習します。実験結果は、同じパラメータスケールでこの方法がパフォーマンスを大幅に向上させることを示しています。したがって、1.3Bおよび14Bモデルの両方でこのアーキテクチャを実装しています。
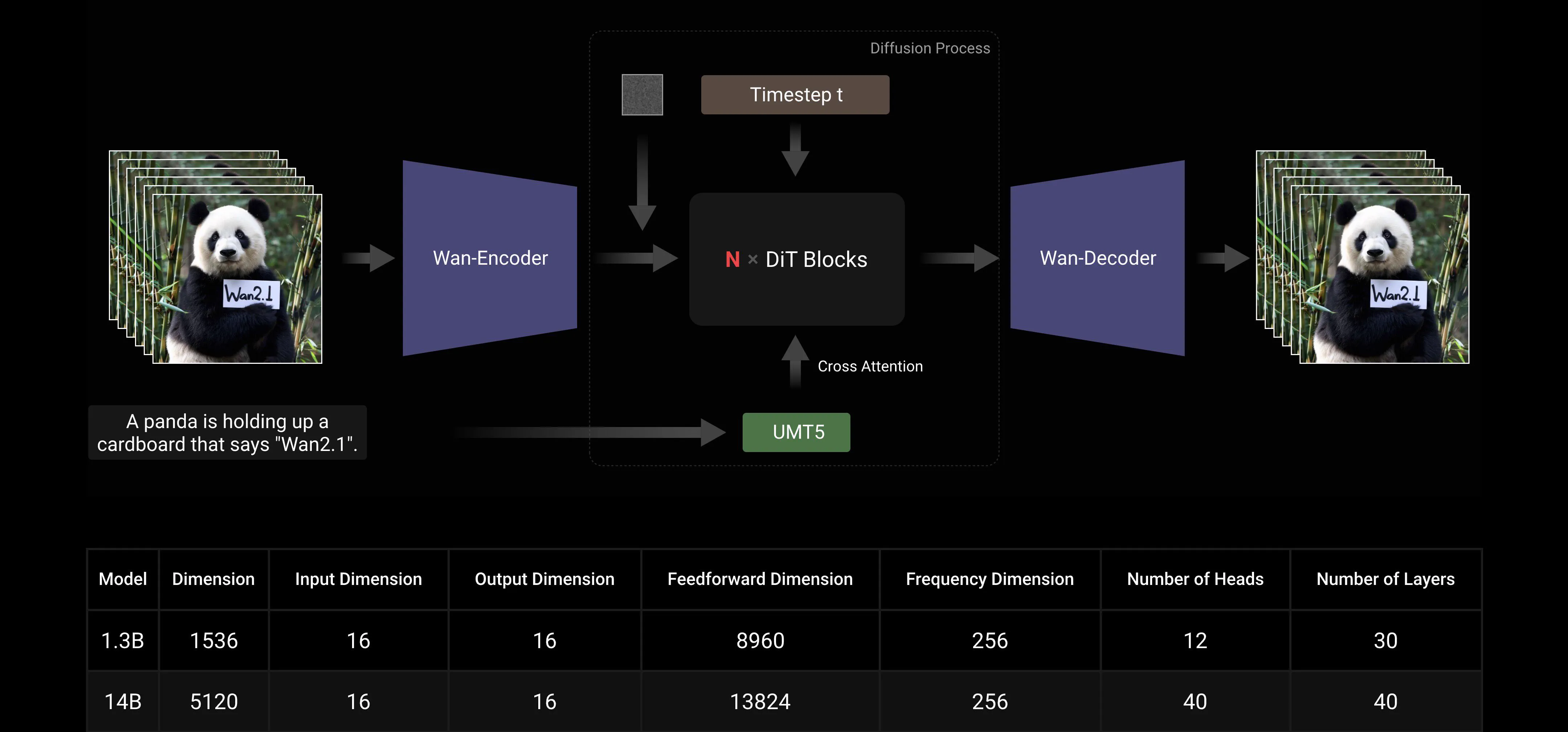
モデルのスケーリングとトレーニング効率
トレーニング中には、FSDPを使用してモデルをシャーディングします。これが上下文並行(CP)と組み合わされると、FSDPグループとCPグループが交差し、モデル並行(MP)とCP/DPの入れ子になることはありません。FSDP内で、DPサイズはFSDPサイズをCPサイズで割ったものに等しくなります。メモリとシングルバッチレイテンシの要件を満たした後、DPをスケーリングに使用します。
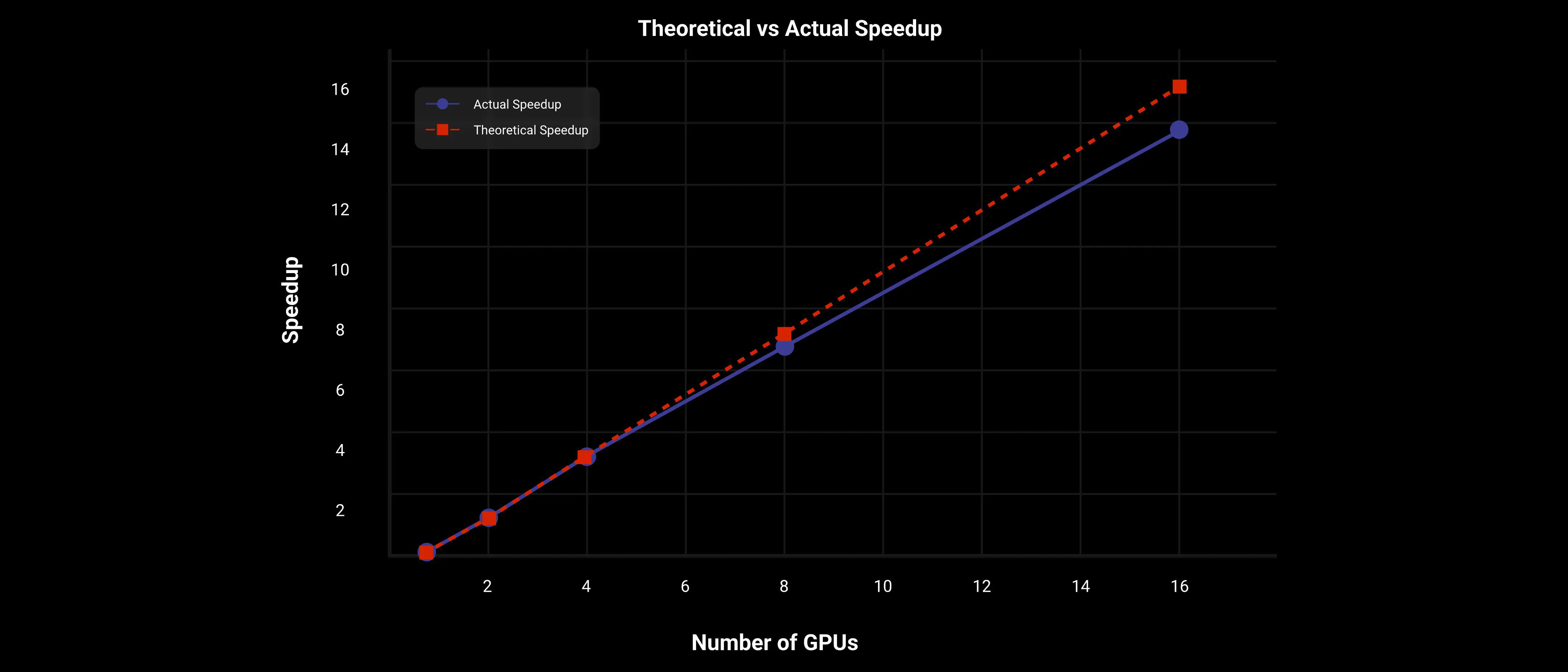
推論中には、単一のビデオの生成レイテンシを減らすために、複数のGPUにスケーリングする際に分散アクセラレーションにコンテキスト並行を選択する必要があります。さらに、モデルが大きい場合はモデルシャーディングが必要です。
シャーディング戦略:14Bなどの大規模モデルの場合、モデルシャーディングを検討する必要があります。シーケンス長が通常長いため、FSDPの通信オーバーヘッドが少なく、計算の重複が可能です。したがって、モデルシャーディングにはFSDP方法を選択し、トレーニング方法と一致させます(注:重みのみをシャーディングし、データ並行は実装しません)。
コンテキスト並行戦略:トレーニングプロセスで使用するのと同じ2Dコンテキスト並行方法を使用します。外側(マシン間)にはRingAttentionを使用し、内側(マシン内)にはUlyssesを使用します。
Wan AI 2.1 14B大モデルでは、2Dコンテキスト並行とFSDP並行戦略を使用して、DiTがほぼ線形にスケーリングされることを示しています。
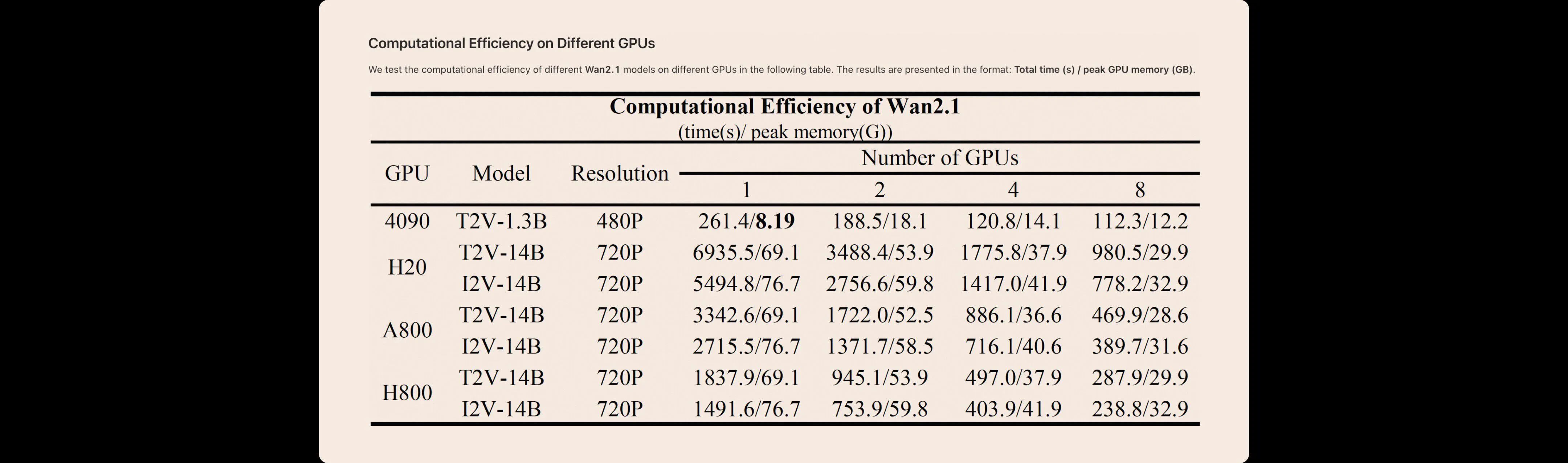
異なるWan AI 2.1モデルの異なるGPUでの計算効率を下表に示します。結果は以下の形式で表示されます:総時間(秒)/ピークGPUメモリ(GB)。
画像からビデオへ
画像からビデオ(I2V)タスクは、入力プロンプトに基づいて与えられた画像をアニメーション化してビデオにすることを目的としており、ビデオ生成の制御性を向上させます。追加の条件画像を最初のフレームとして使用して、ビデオの合成を制御します。具体的には、条件画像はゼロフィルフレームと時間軸に沿って連結され、ガイドフレームを形成します。これらのガイドフレームは、3D変分オートエンコーダ(VAE)によって条件潜在表現に圧縮されます。さらに、生成する必要があるフレームを示す0と保持するフレームを示す1のバイナリマスクを導入します。マスクの空間サイズは条件潜在表現と一致しますが、マスクの時間長さはターゲットビデオと同じです。その後、マスクはVAEの時間ステップに対応する特定の形状に再配置されます。ノイズ潜在表現、条件潜在表現、再配置されたマスクはチャネル軸に沿って連結され、提案されたDiTモデルを通過します。I2V DiTモデルへの入力には、T2Vモデルよりも多くのチャネルがあるため、追加の投影層を使用します。初期値はゼロです。さらに、CLIP画像エンコーダーを使用して条件画像から特徴表現を抽出します。これらの抽出された特徴は、三層の多層パーセプトロン(MLP)によって投影され、グローバルコンテキストとして機能します。その後、解離クロスアテンションを介してこのグローバルコンテキストがDiTモデルに注入されます。
データ
内部著作権データと公開データから15億のビデオと100億の画像を収集し、重複を排除して候補データセットを作成しました。プレトレーニング段階では、この広大でノイズの多いデータセットから高品質で多様なデータを選択し、効果的なトレーニングを行うことを目指します。データマイニングプロセスでは、基本的な次元、視覚的な品質、動きの品質に焦点を当てた4段階のデータクリーニングプロセスを設計しました。
SOTAとの比較
内部著作権データと公開データから15億のビデオと100億の画像を収集し、重複を排除して候補データセットを作成しました。プレトレーニング段階では、この広大でノイズの多いデータセットから高品質で多様なデータを選択し、効果的なトレーニングを行うことを目指します。データマイニングプロセスでは、基本的な次元、視覚的な品質、動きの品質に焦点を当てた4段階のデータクリーニングプロセスを設計しました。
異なるWan AI 2.1モデルの異なるGPUでの計算効率を下表に示します。結果は以下の形式で表示されます:総時間(秒)/ピークGPUメモリ(GB)。