Alibaba Cloud का वीडियो जनरेशन मॉडल, Wan 2.1 (Wan), Apache 2.0 लाइसेंस के तहत ओपन-सोर्स किया गया है। इस रिलीज़ में 14B और 1.3B पैरामीटर वर्ज़न के लिए सभी इंफेरेंस कोड और वेट्स शामिल हैं, जो टेक्स्ट-टू-वीडियो और इमेज-टू-वीडियो टास्क्स को सपोर्ट करते हैं। दुनिया भर के डेवलपर्स GitHub, HuggingFace, और Modao कम्युनिटी पर मॉडल को एक्सेस और अनुभव कर सकते हैं।
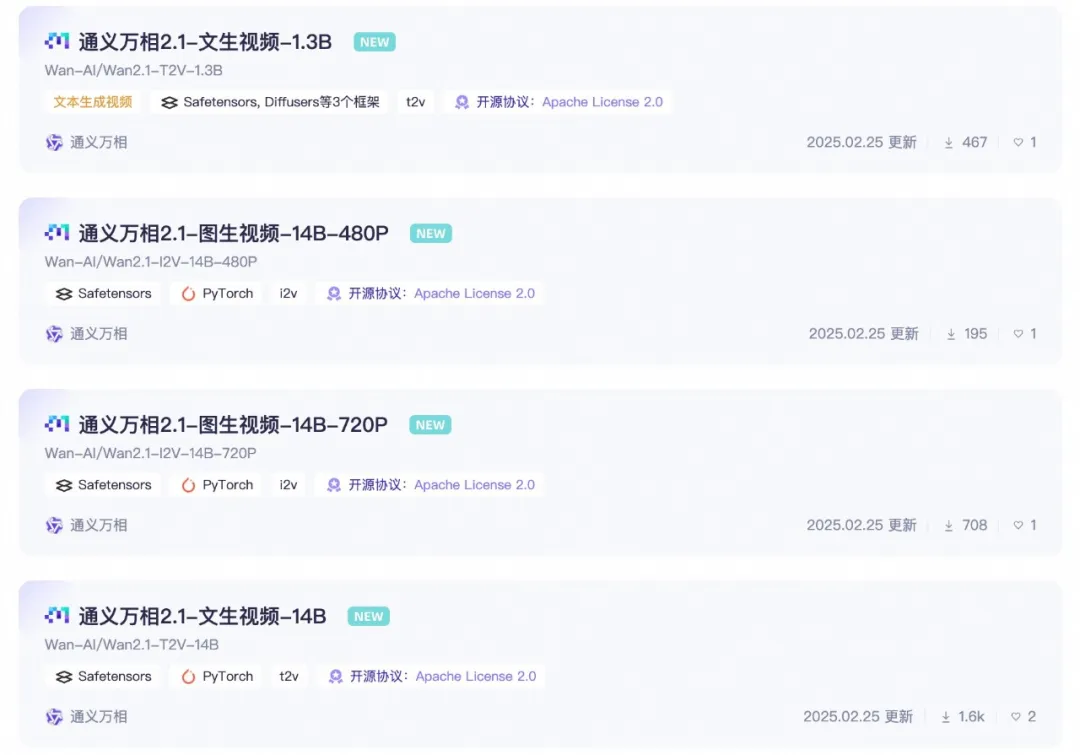
मॉडल के ओपन-सोर्स पैरामीटर वर्ज़न:
Wan 2.1 मॉडल का 14B वर्ज़न
- परफॉर्मेंस: इंस्ट्रक्शन फॉलोइंग, कॉम्प्लेक्स मोशन जनरेशन, फिजिकल मॉडलिंग, और टेक्स्ट-टू-वीडियो जनरेशन में उत्कृष्ट।
- बेंचमार्क: अथॉरिटेटिव VBench इवैल्यूएशन सेट में 86.22% का टोटल स्कोर हासिल किया, जो Sora, Luma, और Pika जैसे अन्य मॉडल्स को काफी पीछे छोड़ता है और पहले स्थान पर है।
Wan 2.1 मॉडल का 1.3B वर्ज़न
- परफॉर्मेंस: बड़े ओपन-सोर्स मॉडल्स को पीछे छोड़ता है और कुछ क्लोज्ड-सोर्स मॉडल्स के साथ मेल खाता है।
- हार्डवेयर आवश्यकताएं: केवल 8.2GB VRAM वाले कंज्यूमर-ग्रेड GPU पर चल सकता है, 480P वीडियो जनरेट करने में सक्षम।
- एप्लिकेशन्स: सेकेंडरी मॉडल डेवलपमेंट और अकादमिक रिसर्च के लिए उपयुक्त।
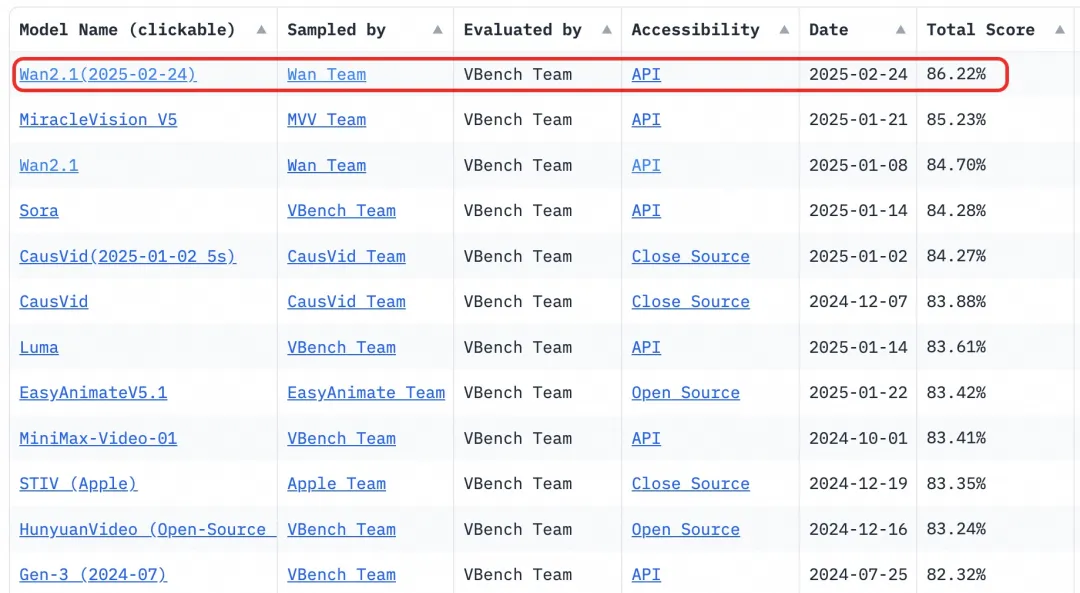
2023 से, Alibaba Cloud बड़े मॉडल्स को ओपन-सोर्स करने के लिए प्रतिबद्ध है। Qwen से डेरिवेटिव मॉडल्स की संख्या 100,000 से अधिक हो गई है, जो इसे ग्लोबली सबसे बड़ा AI मॉडल फैमिली बनाता है। Wan 2.1 के ओपन-सोर्स होने के साथ, Alibaba Cloud ने अब अपने दो फाउंडेशनल मॉडल्स को पूरी तरह से ओपन-सोर्स कर दिया है, जिससे मल्टीमॉडल, फुल-स्केल बड़े मॉडल्स का ओपन-सोर्स स्टेटस हासिल हो गया है।
Wan 2.1 (Wan) मॉडल का टेक्निकल एनालिसिस
मॉडल परफॉर्मेंस
Wan 2.1 मॉडल विभिन्न इंटरनल और एक्सटर्नल बेंचमार्क टेस्ट्स में मौजूदा ओपन-सोर्स मॉडल्स और टॉप कमर्शियल क्लोज्ड-सोर्स मॉडल्स को पीछे छोड़ता है। यह स्पिनिंग, जंपिंग, टर्निंग, और रोलिंग जैसे कॉम्प्लेक्स ह्यूमन बॉडी मूवमेंट्स को स्थिरता से प्रदर्शित कर सकता है, और कॉलिज़न, रिबाउंड, और कट्स जैसे कॉम्प्लेक्स रियल-वर्ल्ड फिजिकल सीनारियो को सटीकता से पुन: उत्पन्न कर सकता है।

इंस्ट्रक्शन-फॉलोइंग क्षमताओं के मामले में, मॉडल चीनी और अंग्रेजी दोनों में लंबे टेक्स्टुअल इंस्ट्रक्शन को सटीकता से समझ सकता है, और विभिन्न सीन ट्रांजिशन्स और कैरेक्टर इंटरैक्शन्स को वफादारी से पुन: उत्पन्न कर सकता है।

की टेक्नोलॉजीज
मुख्यधारा के DiT और लीनियर नॉइज़ शेड्यूल Flow Matching पैराडाइम्स पर आधारित, Wan AI लार्ज मॉडल ने जनरेटिव क्षमताओं में महत्वपूर्ण प्रगति की है, जिसमें एक एफिशिएंट कॉज़ल 3D VAE, स्केलेबल प्री-ट्रेनिंग स्ट्रैटेजीज, लार्ज-स्केल डेटा पाइपलाइन्स का निर्माण, और ऑटोमेटेड इवैल्यूएशन मेट्रिक्स का कार्यान्वयन शामिल है। इन इनोवेशन्स ने मिलकर मॉडल की समग्र परफॉर्मेंस को बढ़ाया है।
एफिशिएंट कॉज़ल 3D VAE: Wan AI ने वीडियो जनरेशन के लिए विशेष रूप से डिज़ाइन किए गए एक नए कॉज़ल 3D VAE आर्किटेक्चर का विकास किया है, जिसमें स्पेसियोटेम्पोरल कंप्रेशन को बेहतर बनाने, मेमोरी यूज़ेज को कम करने, और टेम्पोरल कॉज़लिटी को सुनिश्चित करने के लिए विभिन्न स्ट्रैटेजीज शामिल हैं।
वीडियो डिफ्यूज़न ट्रांसफॉर्मर: Wan AI मॉडल आर्किटेक्चर मुख्यधारा के वीडियो डिफ्यूज़न ट्रांसफॉर्मर स्ट्रक्चर पर आधारित है। यह Full Attention मेकेनिज्म के माध्यम से लॉन्ग-टर्म स्पेसियोटेम्पोरल डिपेंडेंसीज़ के प्रभावी मॉडलिंग को सुनिश्चित करता है, जिससे टेम्पोरली और स्पेसियली कंसिस्टेंट वीडियो जनरेशन हासिल होता है।
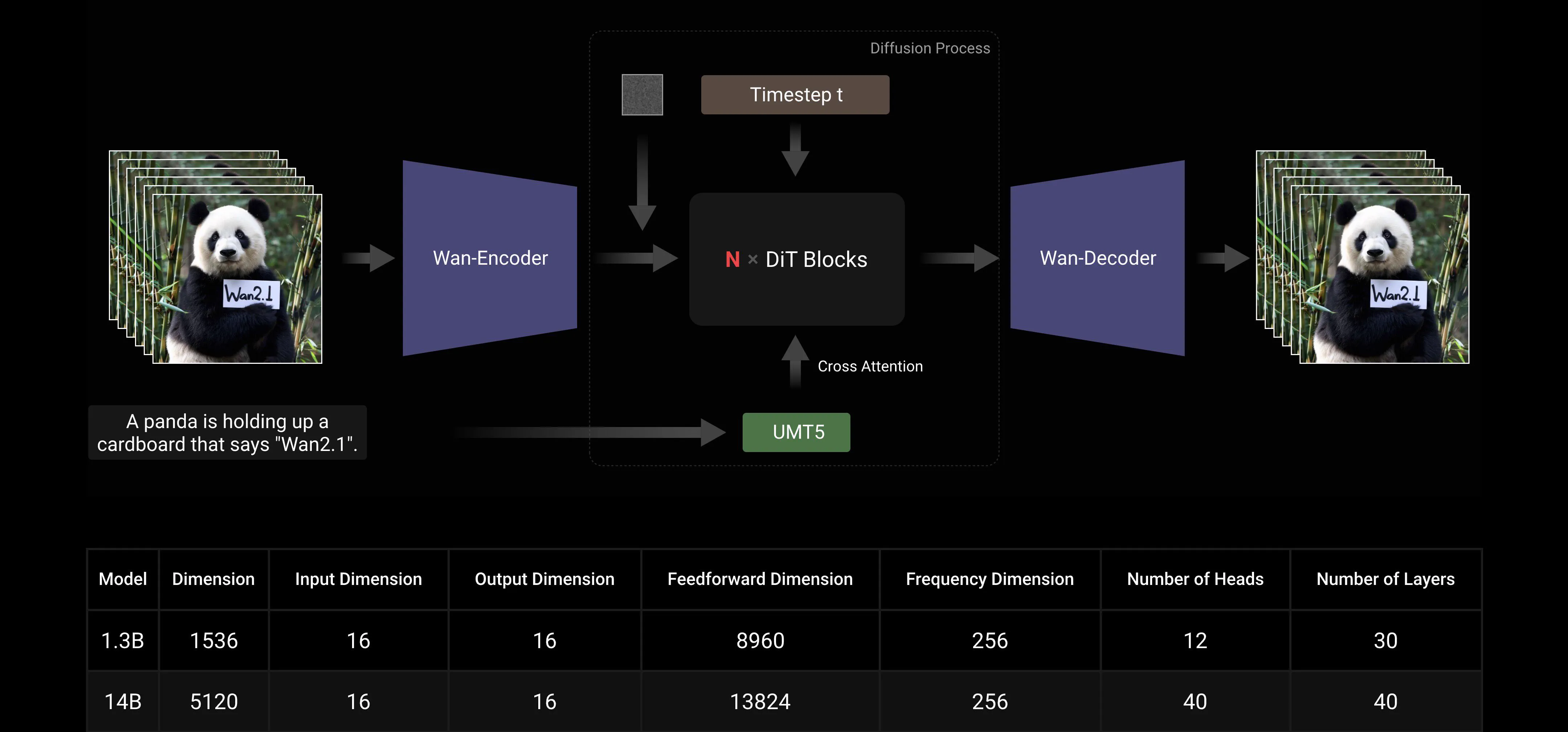
मॉडल ट्रेनिंग और इंफेरेंस एफिशिएंसी ऑप्टिमाइज़ेशन: ट्रेनिंग फेज़ के दौरान, टेक्स्ट और वीडियो एन्कोडिंग मॉड्यूल्स के लिए, हम Data Parallelism (DP) और Fully Sharded Data Parallelism (FSDP) को मिलाकर एक डिस्ट्रिब्यूटेड स्ट्रैटेजी अपनाते हैं। DiT मॉड्यूल के लिए, हम DP, FSDP, RingAttention, और Ulysses को मिलाकर एक हाइब्रिड पैरेलल स्ट्रैटेजी अपनाते हैं। इंफेरेंस फेज़ के दौरान, मल्टीपल GPU का उपयोग करके एक सिंगल वीडियो जनरेट करने की लेटेंसी को कम करने के लिए, हमें Collective Parallelism (CP) को डिस्ट्रिब्यूटेड एक्सेलेरेशन के लिए चुनना होता है। इसके अलावा, जब मॉडल बड़ा होता है, तो मॉडल स्लाइसिंग की भी आवश्यकता होती है।

ओपन-सोर्स कम्युनिटी फ्रेंडली
Wan AI ने GitHub और Hugging Face पर मल्टीपल मुख्यधारा के फ्रेमवर्क्स को पूरी तरह से सपोर्ट किया है। यह पहले से ही Gradio अनुभव और xDiT के साथ पैरेलल एक्सेलेरेटेड इंफेरेंस को सपोर्ट करता है। Diffusers और ComfyUI के साथ इंटीग्रेशन भी तेजी से कार्यान्वित किया जा रहा है, जिससे डेवलपर्स के लिए वन-क्लिक इंफेरेंस डिप्लॉयमेंट को सुविधाजनक बनाया जा सके। यह न केवल डेवलपमेंट थ्रेशोल्ड को कम करता है, बल्कि विभिन्न आवश्यकताओं वाले यूज़र्स के लिए फ्लेक्सिबल ऑप्शन्स भी प्रदान करता है, चाहे वह रैपिड प्रोटोटाइपिंग के लिए हो या एफिशिएंट प्रोडक्शन डिप्लॉयमेंट के लिए।
ओपन-सोर्स कम्युनिटी लिंक्स:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
अपेंडिक्स: Wan AI मॉडल डेमो शोकेस
पहला वीडियो जनरेशन मॉडल जो चीनी टेक्स्ट जनरेशन को सपोर्ट करता है और साथ ही चीनी और अंग्रेजी दोनों में टेक्स्ट इफेक्ट्स जनरेशन को सक्षम बनाता है:
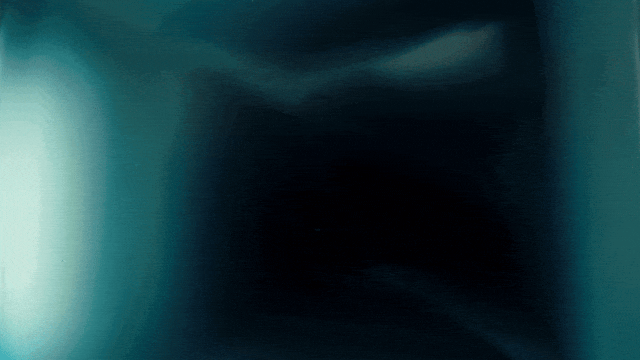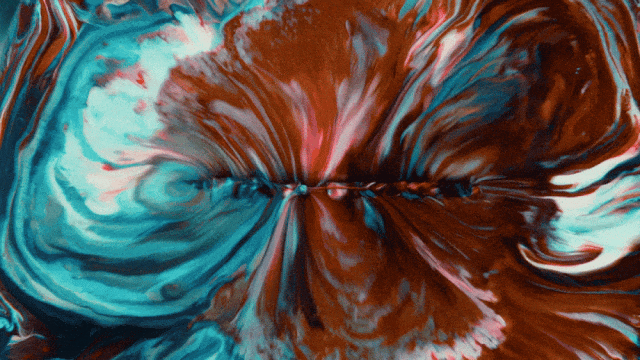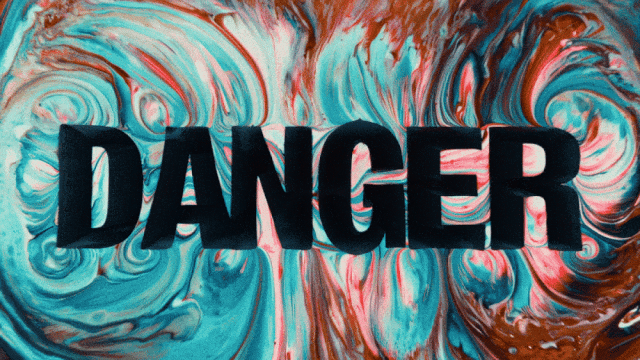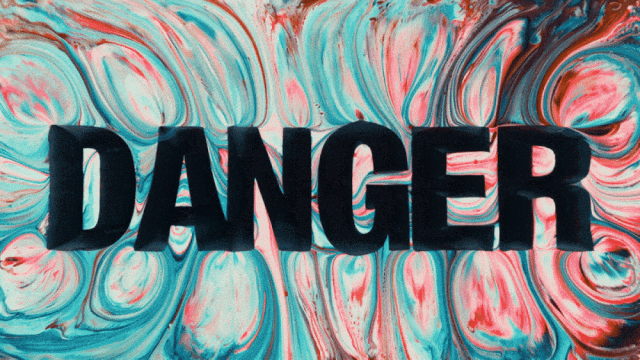
 अधिक स्थिर और जटिल मोशन जनरेशन क्षमताएं:
अधिक स्थिर और जटिल मोशन जनरेशन क्षमताएं:

 अधिक लचीली कैमरा कंट्रोल क्षमताएं::
अधिक लचीली कैमरा कंट्रोल क्षमताएं::

 उन्नत टेक्स्चर, विविध स्टाइल्स, और मल्टीपल एस्पेक्ट रेशियो:
उन्नत टेक्स्चर, विविध स्टाइल्स, और मल्टीपल एस्पेक्ट रेशियो:
 इमेज-टू-वीडियो जनरेशन, जिससे क्रिएशन को अधिक कंट्रोलेबल बनाया जा सके:
इमेज-टू-वीडियो जनरेशन, जिससे क्रिएशन को अधिक कंट्रोलेबल बनाया जा सके:

