Le modèle de génération vidéo d'Alibaba Cloud, Wan 2.1 (Wan), a été open-sourcé sous la licence Apache 2.0. Cette version inclut tout le code d'inférence et les poids pour les versions 14B et 1.3B, supportant à la fois les tâches de texte-à-vidéo et d'image-à-vidéo. Les développeurs du monde entier peuvent accéder et expérimenter le modèle sur GitHub, HuggingFace, et la communauté Modao.
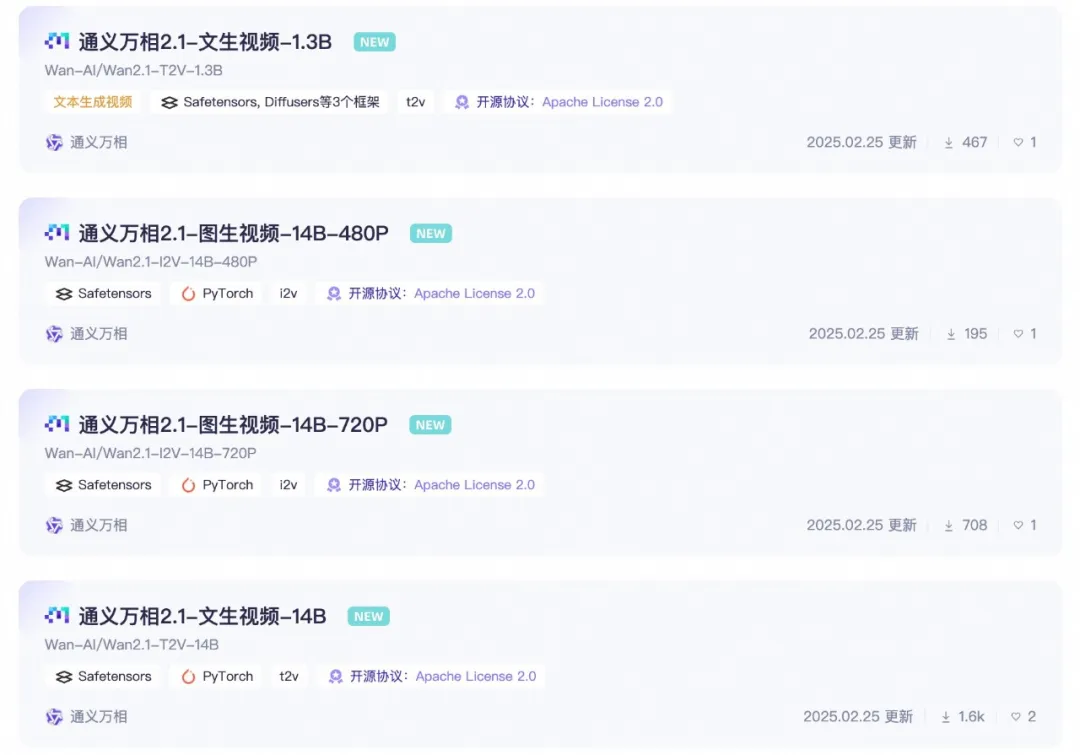
Versions Open-Sourcées des Paramètres du Modèle :
Version 14B du Modèle Wan 2.1
- Performance : Excelle dans le suivi des instructions, la génération de mouvements complexes, la modélisation physique, et la génération de texte-à-vidéo.
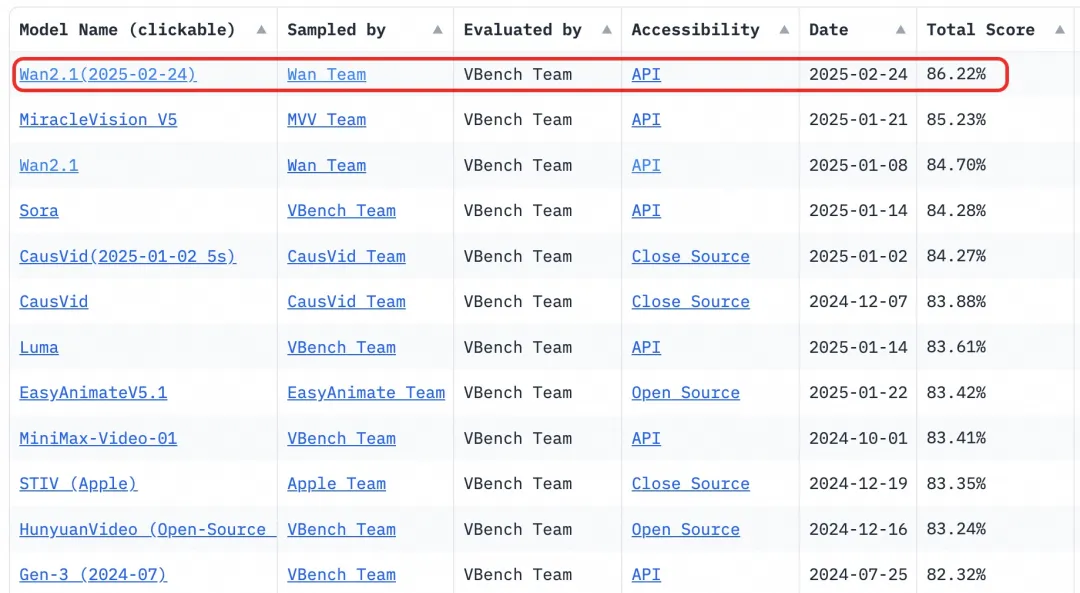
- Benchmark : A obtenu un score total de 86,22% dans l'ensemble d'évaluation VBench, surpassant significativement d'autres modèles comme Sora, Luma, et Pika, et se classant premier.
Version 1.3B du Modèle Wan 2.1
- Performance : Surpasse les modèles open-source plus grands et rivalise même avec certains modèles propriétaires.
- Exigences Matérielles : Peut fonctionner sur des GPU grand public avec seulement 8,2 Go de VRAM, capable de générer des vidéos 480P.
- Applications : Convient pour le développement de modèles secondaires et la recherche académique.
Depuis 2023, Alibaba Cloud s'est engagé à open-sourcer les grands modèles. Le nombre de modèles dérivés de Qwen a dépassé 100 000, en faisant la plus grande famille de modèles IA au monde. Avec l'open-sourcing de Wan 2.1, Alibaba Cloud a maintenant entièrement open-sourcé ses deux modèles fondamentaux, atteignant le statut open-source pour les modèles multimodaux et à grande échelle.
Analyse Technique du Modèle Wan 2.1 (Wan)
Performance du Modèle
Le modèle Wan 2.1 surpasse les modèles open-source existants et les meilleurs modèles propriétaires dans divers tests de référence internes et externes. Il peut démontrer de manière stable des mouvements complexes du corps humain tels que la rotation, le saut, le virage et le roulis, et reproduire avec précision des scénarios physiques complexes du monde réel comme les collisions, les rebonds et les coupures.

En termes de capacités de suivi des instructions, le modèle peut comprendre avec précision les instructions textuelles longues en chinois et en anglais, reproduisant fidèlement diverses transitions de scènes et interactions de personnages.

Technologies Clés
Basé sur les paradigmes DiT et Flow Matching, le Grand Modèle Wan AI a réalisé des progrès significatifs dans les capacités génératives grâce à une série d'innovations technologiques. Celles-ci incluent le développement d'un VAE 3D causal efficace, des stratégies de pré-entraînement évolutives, la construction de pipelines de données à grande échelle, et la mise en œuvre de métriques d'évaluation automatisées. Ensemble, ces innovations ont amélioré la performance globale du modèle.
VAE 3D Causal Efficace : Wan AI a développé une nouvelle architecture VAE 3D causal spécifiquement conçue pour la génération vidéo, incorporant diverses stratégies pour améliorer la compression spatio-temporelle, réduire l'utilisation de la mémoire et assurer la causalité temporelle.
Video Diffusion Transformer : L'architecture du modèle Wan AI est basée sur la structure Video Diffusion Transformer. Elle assure une modélisation efficace des dépendances spatio-temporelles à long terme grâce au mécanisme Full Attention, permettant une génération vidéo cohérente dans le temps et l'espace.
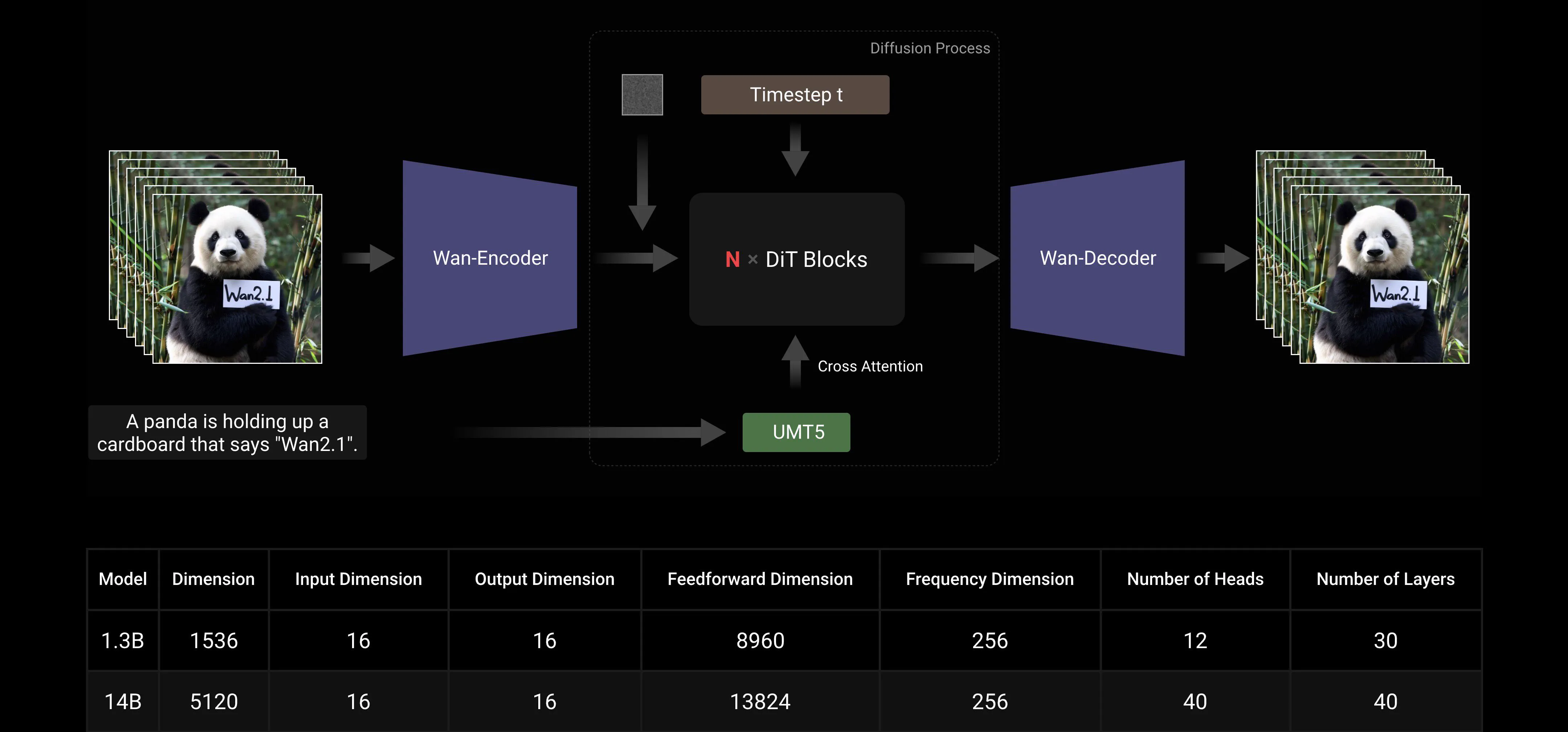
Optimisation de l'Efficacité de l'Entraînement et de l'Inférence : Pendant la phase d'entraînement, pour les modules d'encodage de texte et vidéo, nous employons une stratégie distribuée combinant Data Parallelism (DP) et Fully Sharded Data Parallelism (FSDP). Pour le module DiT, nous adoptons une stratégie parallèle hybride intégrant DP, FSDP, RingAttention, et Ulysses. Pendant la phase d'inférence, pour réduire la latence de génération d'une seule vidéo en utilisant plusieurs GPU, nous devons sélectionner Collective Parallelism (CP) pour l'accélération distribuée. De plus, lorsque le modèle est grand, le découpage du modèle est également nécessaire.

Communauté Open-Source Amicale
Wan AI a entièrement supporté plusieurs frameworks mainstream sur GitHub et Hugging Face. Il supporte déjà l'expérience Gradio et l'inférence accélérée parallèle avec xDiT. L'intégration avec Diffusers et ComfyUI est également en cours de mise en œuvre rapide pour faciliter le déploiement d'inférence en un clic pour les développeurs. Cela non seulement abaisse le seuil de développement mais fournit également des options flexibles pour les utilisateurs avec des besoins différents, que ce soit pour le prototypage rapide ou le déploiement de production efficace.
Liens de la Communauté Open-Source :
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Annexe : Démonstration du Modèle Wan AI
Le premier modèle de génération vidéo qui supporte la génération de texte en chinois et permet simultanément la génération d'effets de texte en chinois et en anglais :
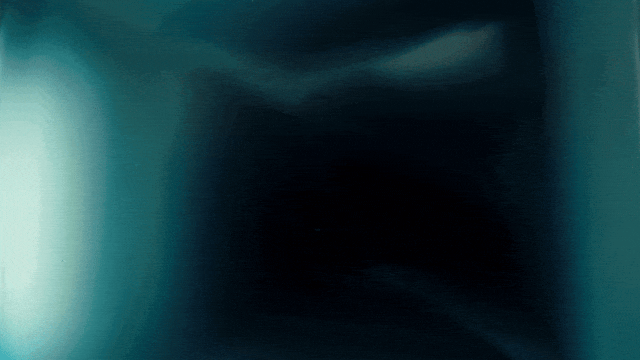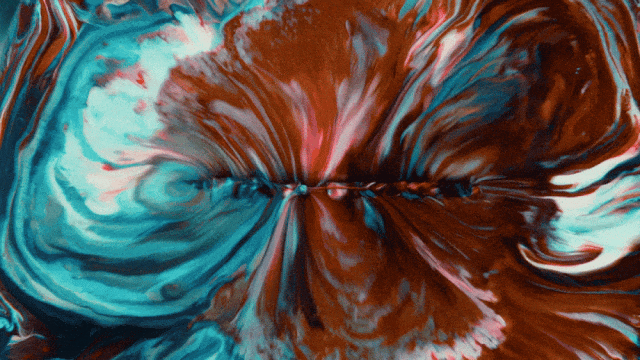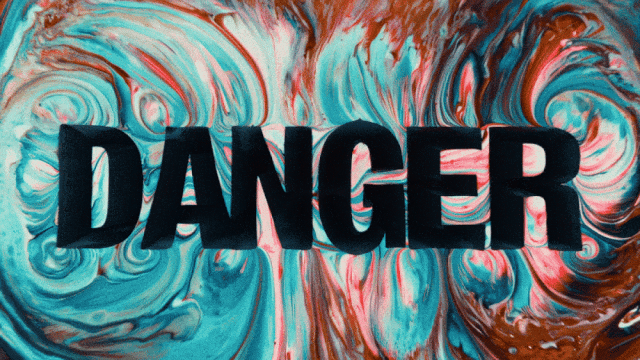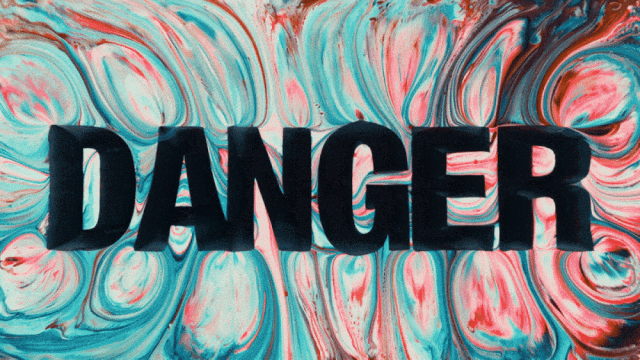
 Capacités de Génération de Mouvements Plus Stables et Complexes :
Capacités de Génération de Mouvements Plus Stables et Complexes :

 Capacités de Contrôle de Caméra Plus Flexibles :
Capacités de Contrôle de Caméra Plus Flexibles :

 Textures Avancées, Styles Divers et Ratios d'Aspect Multiples :
Textures Avancées, Styles Divers et Ratios d'Aspect Multiples :

 Génération Image-à-Vidéo, Rendant la Création Plus Contrôlable :
Génération Image-à-Vidéo, Rendant la Création Plus Contrôlable :

