Rapport Technique
Restez à l'écoute pour la publication prochaine de notre rapport technique complet pour plus de détails.
Basé sur le paradigme de transformation de diffusion courant, Wan 2.1 réalise des avancées significatives en capacités génératives grâce à une série d'innovations, y compris notre nouvel autoencodeur variationnel spatio-temporel (VAE), des stratégies de pré-entraînement évolutives, la construction de données à grande échelle et des métriques d'évaluation automatisées. Ces contributions améliorent collectivement la performance et la polyvalence du modèle.
Autoencodeurs Variationnels 3D
Nous proposons une nouvelle architecture VAE causale 3D spécialement conçue pour la génération vidéo. Nous combinons plusieurs stratégies pour améliorer la compression spatio-temporelle, réduire l'utilisation de la mémoire et assurer la causalité temporelle. Ces améliorations rendent notre VAE plus efficace, évolutif et mieux adapté à l'intégration avec des modèles génératifs basés sur la diffusion comme DiT.
Nous implémentons un mécanisme de cache de caractéristiques dans le module de convolution causale de la VAE 3D. Plus précisément, le nombre de trames de la séquence vidéo suit le format d'entrée 1 + T, nous divisons donc la vidéo en morceaux 1 + T/4, ce qui est cohérent avec le nombre de caractéristiques latentes. Lors du traitement des séquences vidéo d'entrée, le modèle utilise une stratégie par morceaux où chaque opération de codage et de décodage ne traite que le morceau vidéo correspondant à une seule représentation latente. Sur la base du taux de compression temporelle, le nombre de trames dans chaque morceau de traitement est limité à 4 au maximum, ce qui empêche efficacement le dépassement de la mémoire GPU.
Les résultats expérimentaux indiquent que notre VAE vidéo présente des performances hautement compétitives sur les deux métriques, démontrant un avantage concurrentiel de qualité vidéo supérieure et de haute efficacité de traitement. Il est à noter que dans le même environnement matériel (c'est-à-dire un seul GPU A800), la vitesse de reconstruction de notre VAE est 2,5 fois plus rapide que la méthode SOTA existante (c'est-à-dire HunYuanVideo). Cet avantage de vitesse sera encore plus évident à des résolutions plus élevées en raison de la conception compacte de notre modèle VAE et du mécanisme de cache de caractéristiques.
DiT de Diffusion Vidéo
Wan AI 2.1 est conçu en utilisant le cadre d'appariement de flux dans le paradigme des Transformateurs de Diffusion courants. Dans l'architecture de notre modèle, nous utilisons l'Encodeur T5 pour encoder les entrées textuelles multilingues, incorporant l'attention croisée dans chaque bloc de transformateur pour intégrer le texte dans la structure du modèle. De plus, nous utilisons une couche linéaire et une couche SiLU pour traiter les entrées temporelles et prédire six paramètres de modulation individuellement. Ce MLP est partagé entre tous les blocs de transformateurs, chaque bloc apprenant un ensemble distinct de biais. Nos résultats expérimentaux montrent une amélioration significative des performances à la même échelle de paramètres. Par conséquent, nous implémentons cette architecture à la fois dans les modèles 1.3B et 14B.
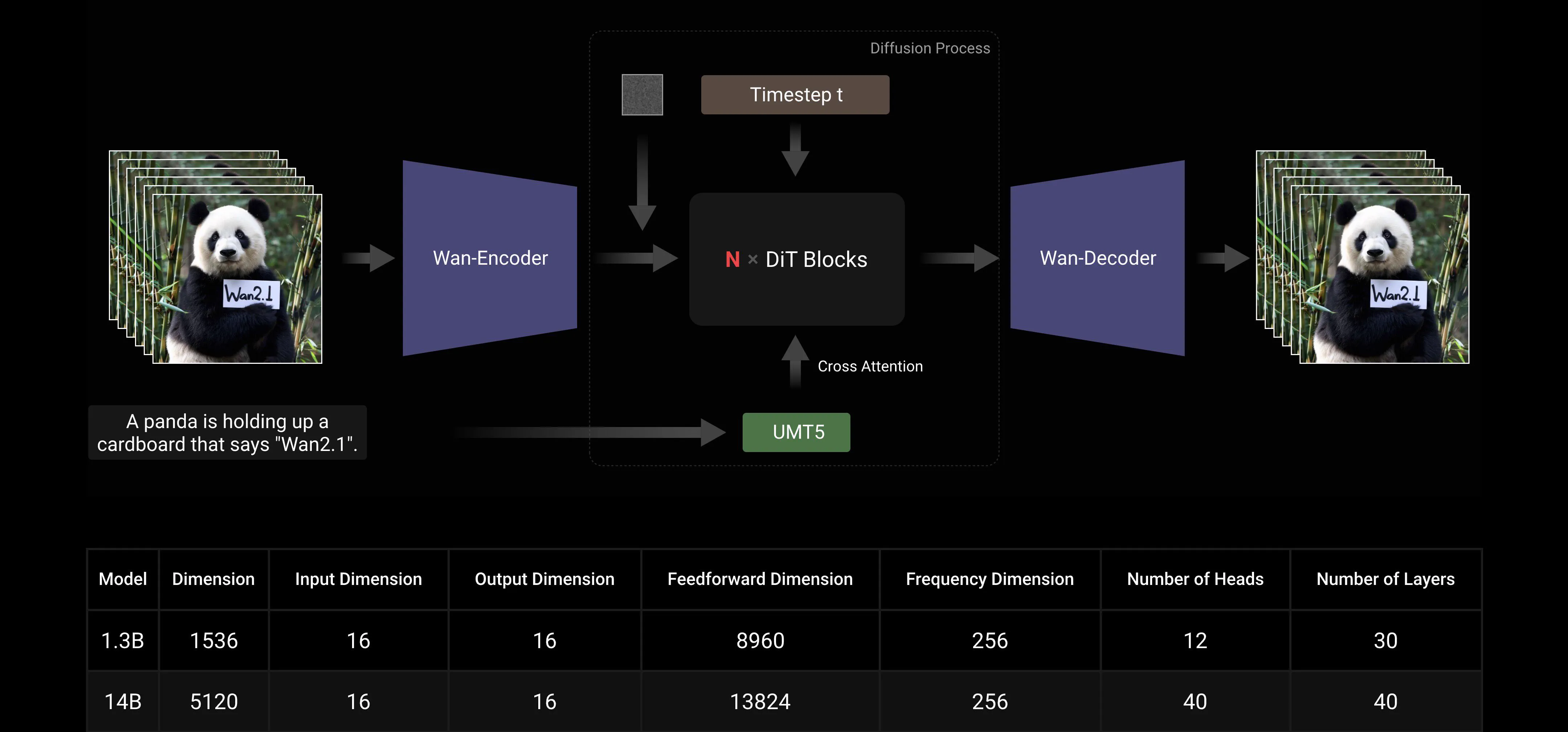
Mise à l'Échelle du Modèle et Efficacité de l'Entraînement
Pendant l'entraînement, nous utilisons FSDP pour le partitionnement du modèle, qui, lorsqu'il est combiné avec le parallélisme de contexte (CP), forme une combinaison imbriquée de parallélisme de modèle (MP) et de CP/DP, plutôt qu'une combinaison imbriquée de MP et CP/DP. Au sein de FSDP, la taille de DP est égale à la taille de FSDP divisée par la taille de CP. Après avoir satisfait les exigences de mémoire et de latence de lot unique, nous utilisons DP pour la mise à l'échelle.
Lors de l'inférence, pour réduire la latence de génération d'une seule vidéo lors de la mise à l'échelle sur plusieurs GPU, il est nécessaire de sélectionner le parallélisme de contexte pour l'accélération distribuée. De plus, lorsque le modèle est grand, le partitionnement du modèle est requis.
Stratégie de Partitionnement du Modèle : Pour les grands modèles comme le 14B, le partitionnement du modèle doit être envisagé. Étant donné que les longueurs de séquence sont généralement longues, FSDP entraîne moins de surcharge de communication par rapport à TP et permet le chevauchement des calculs. Par conséquent, nous choisissons la méthode FSDP pour le partitionnement du modèle, cohérente avec notre approche d'entraînement (remarque : partitionner uniquement les poids sans implémenter le parallélisme de données).
Stratégie de Parallélisme de Contexte : Utilisation de la même approche de parallélisme de contexte 2D que lors de l'entraînement : utilisation de RingAttention pour la couche externe (inter-machine) et d'Ulysses pour la couche interne (intra-machine).
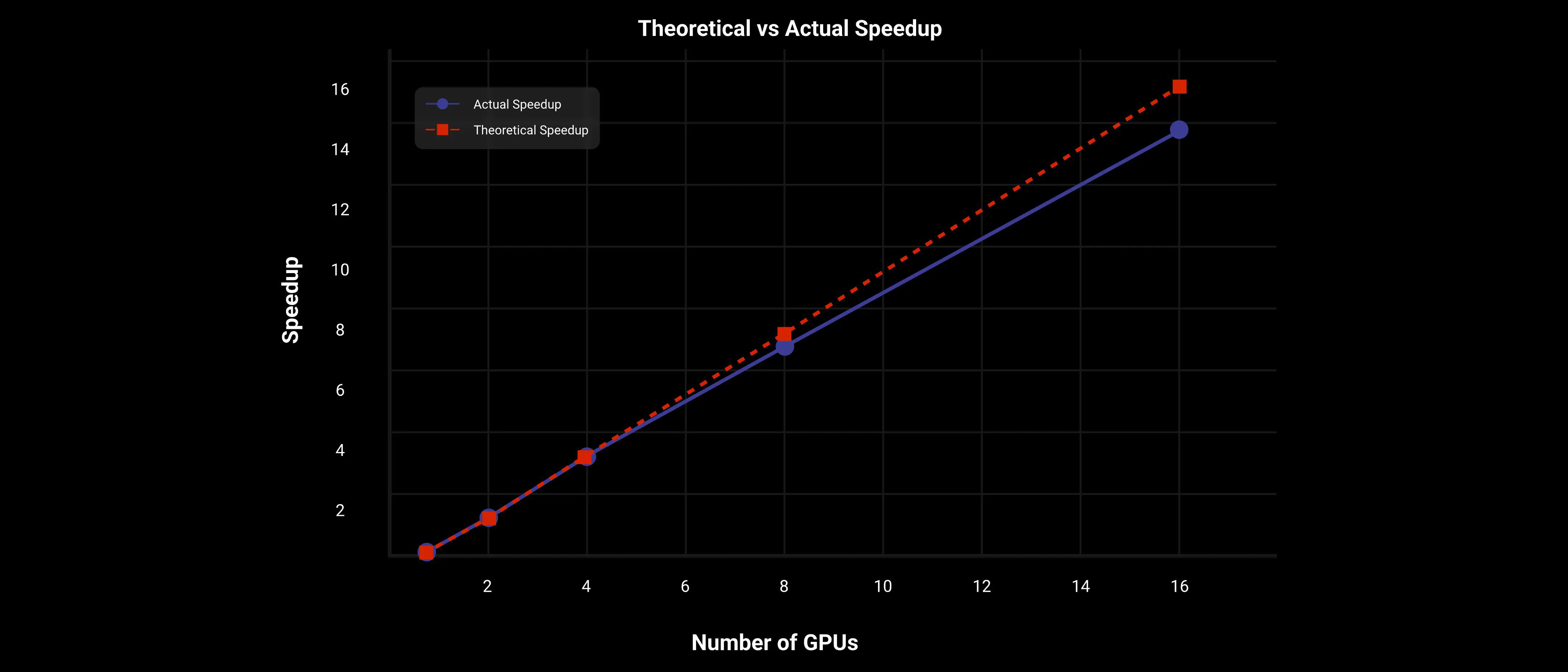
Sur le grand modèle Wan AI 2.1 14B, en utilisant la stratégie de parallélisme 2D Contextuel et FSDP, DiT atteint une accélération presque linéaire, comme le montre le graphique suivant.
Nous testons l'efficacité de calcul de différents modèles Wan AI 2.1 sur différents GPU dans le tableau suivant. Les résultats sont présentés au format : temps total (s) / pic de mémoire GPU (Go).
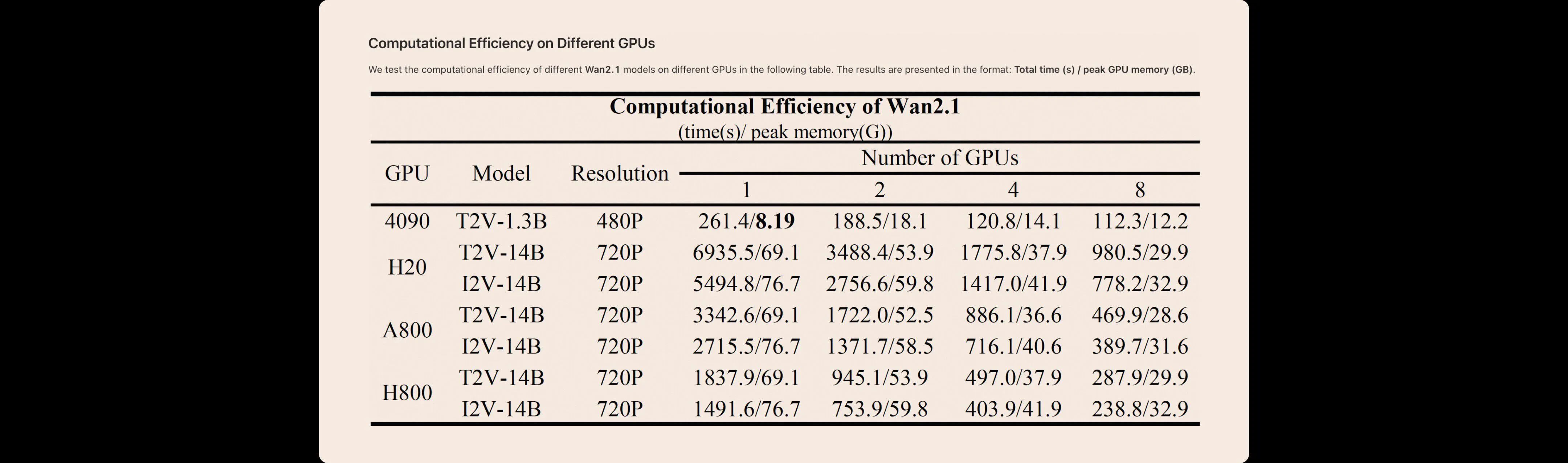
Image en Vidéo
La tâche Image en Vidéo (I2V) vise à animer une image donnée en une vidéo basée sur une description textuelle, améliorant ainsi la contrôlabilité de la génération vidéo. Nous introduisons une image conditionnelle supplémentaire comme première image pour contrôler la synthèse vidéo. Plus précisément, l'image conditionnelle est concaténée avec des images remplies de zéros le long de l'axe temporel, formant des images de guidage. Ces images de guidage sont ensuite compressées par un autoencodeur variationnel 3D (VAE) en une représentation latente conditionnelle. De plus, nous introduisons un masque binaire où 1 indique l'image préservée et 0 indique les images qui doivent être générées. La taille spatiale du masque correspond à la représentation latente conditionnelle, mais la longueur temporelle du masque est la même que celle de la vidéo cible. Ce masque est ensuite réorganisé en une forme spécifique correspondant à la foulée temporelle du VAE. La représentation latente bruitée, la représentation latente conditionnelle et le masque réorganisé sont concaténés le long de l'axe des canaux et passés à travers le modèle DiT proposé. Étant donné que l'entrée du modèle DiT I2V a plus de canaux que le modèle T2V, une couche de projection supplémentaire est utilisée, initialisée avec des valeurs nulles. De plus, nous utilisons un encodeur d'image CLIP pour extraire des représentations de caractéristiques de l'image conditionnelle. Ces caractéristiques extraites sont projetées par un perceptron multicouche à trois couches (MLP), qui sert de contexte global. Ce contexte global est ensuite injecté dans le modèle DiT via une attention croisée découplée.
Données
Nous constituons et dédupliquons un ensemble de données candidat composé de 1,5 milliard de vidéos et 10 milliards d'images, provenant à la fois de sources sous copyright interne et de données accessibles au public. Lors de la phase de pré-entraînement, notre objectif est de sélectionner des données de haute qualité et diversifiées à partir de cet ensemble de données vaste mais bruité pour faciliter un entraînement efficace. Tout au long du processus de nettoyage des données, nous concevons un processus de nettoyage des données en quatre étapes, axé sur les dimensions fondamentales, la qualité visuelle et la qualité du mouvement.
Comparaisons avec SOTA
Nous constituons et dédupliquons un ensemble de données candidat composé de 1,5 milliard de vidéos et 10 milliards d'images, provenant à la fois de sources sous copyright interne et de données accessibles au public. Lors de la phase de pré-entraînement, notre objectif est de sélectionner des données de haute qualité et diversifiées à partir de cet ensemble de données vaste mais bruité pour faciliter un entraînement efficace. Tout au long du processus de nettoyage des données, nous concevons un processus de nettoyage des données en quatre étapes, axé sur les dimensions fondamentales, la qualité visuelle et la qualité du mouvement.
Nous testons l'efficacité de calcul de différents modèles Wan AI 2.1 sur différents GPU dans le tableau suivant. Les résultats sont présentés au format : temps total (s) / pic de mémoire GPU (Go).