Alibaba Clouds Videogenerierungsmodell, Wan 2.1 (Wan), wurde unter der Apache 2.0-Lizenz quelloffen veröffentlicht. Diese Veröffentlichung umfasst den gesamten Inferenzcode und die Gewichte für die 14B- und 1.3B-Parameter-Versionen, die sowohl Text-zu-Video- als auch Bild-zu-Video-Aufgaben unterstützen. Entwickler weltweit können das Modell auf GitHub, HuggingFace und der Modao-Community zugreifen und erleben.
Quelloffene Parameter-Versionen des Modells:
14B-Version des Wan 2.1-Modells
- Leistung: Überzeugt in der Befolgung von Anweisungen, der Generierung komplexer Bewegungen, physikalischer Modellierung und Text-zu-Video-Generierung.
- Benchmark: Erreichte eine Gesamtpunktzahl von 86,22 % im autoritativen VBench-Bewertungsset und übertraf damit andere Modelle wie Sora, Luma und Pika deutlich und belegte den ersten Platz.
1.3B-Version des Wan 2.1-Modells
- Leistung: Übertrifft größere quelloffene Modelle und kann sogar mit einigen proprietären Modellen mithalten.
- Hardware-Anforderungen: Kann auf Consumer-GPUs mit nur 8,2 GB VRAM ausgeführt werden und ist in der Lage, 480P-Videos zu generieren.
- Anwendungen: Geeignet für die Entwicklung von Sekundärmodellen und akademische Forschung.
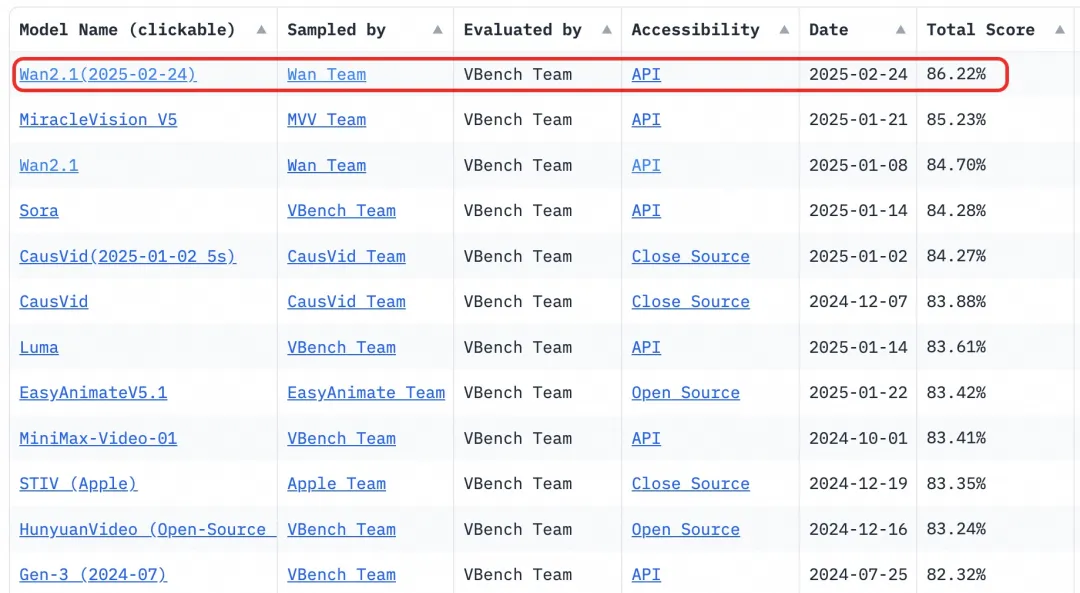
Seit 2023 hat sich Alibaba Cloud der Quelloffenlegung großer Modelle verschrieben. Die Anzahl der abgeleiteten Modelle von Qwen hat 100.000 überschritten, was es zur größten KI-Modellfamilie weltweit macht. Mit der Quelloffenlegung von Wan 2.1 hat Alibaba Cloud nun seine beiden Grundlagenmodelle vollständig quelloffen gemacht und den Status der Quelloffenlegung für multimodale, vollständig skalierte große Modelle erreicht.
Technische Analyse des Wan 2.1 (Wan)-Modells
Modellleistung
Das Wan 2.1-Modell übertrifft bestehende quelloffene Modelle und führende kommerzielle proprietäre Modelle in verschiedenen internen und externen Benchmark-Tests. Es kann stabile komplexe menschliche Bewegungen wie Drehen, Springen, Wenden und Rollen demonstrieren und komplexe reale physikalische Szenarien wie Kollisionen, Rückprall und Schnitte genau reproduzieren.

In Bezug auf die Befolgung von Anweisungen kann das Modell lange textuelle Anweisungen in Chinesisch und Englisch genau verstehen und verschiedene Szenenübergänge und Charakterinteraktionen treu reproduzieren.

Schlüsseltechnologien
Basierend auf den Mainstream-DiT- und linearen Rauschplan-Flow-Matching-Paradigmen hat das Wan AI Large Model durch eine Reihe von technologischen Innovationen bedeutende Fortschritte in den Generierungsfähigkeiten erzielt. Dazu gehören die Entwicklung eines effizienten kausalen 3D-VAE, skalierbare Pre-Training-Strategien, die Konstruktion von groß angelegten Datenpipelines und die Implementierung automatisierter Bewertungsmetriken. Zusammen haben diese Innovationen die Gesamtleistung des Modells verbessert.
Effizienter kausaler 3D VAE: Wan AI hat eine neuartige kausale 3D-VAE-Architektur speziell für die Videogenerierung entwickelt, die verschiedene Strategien zur Verbesserung der raumzeitlichen Kompression, zur Reduzierung des Speicherverbrauchs und zur Sicherstellung der zeitlichen Kausalität enthält.
Video Diffusion Transformer: Die Wan AI-Modellarchitektur basiert auf der Mainstream-Video-Diffusion-Transformer-Struktur. Sie stellt eine effektive Modellierung langfristiger raumzeitlicher Abhängigkeiten durch den Full-Attention-Mechanismus sicher und erreicht eine zeitlich und räumlich konsistente Videogenerierung.
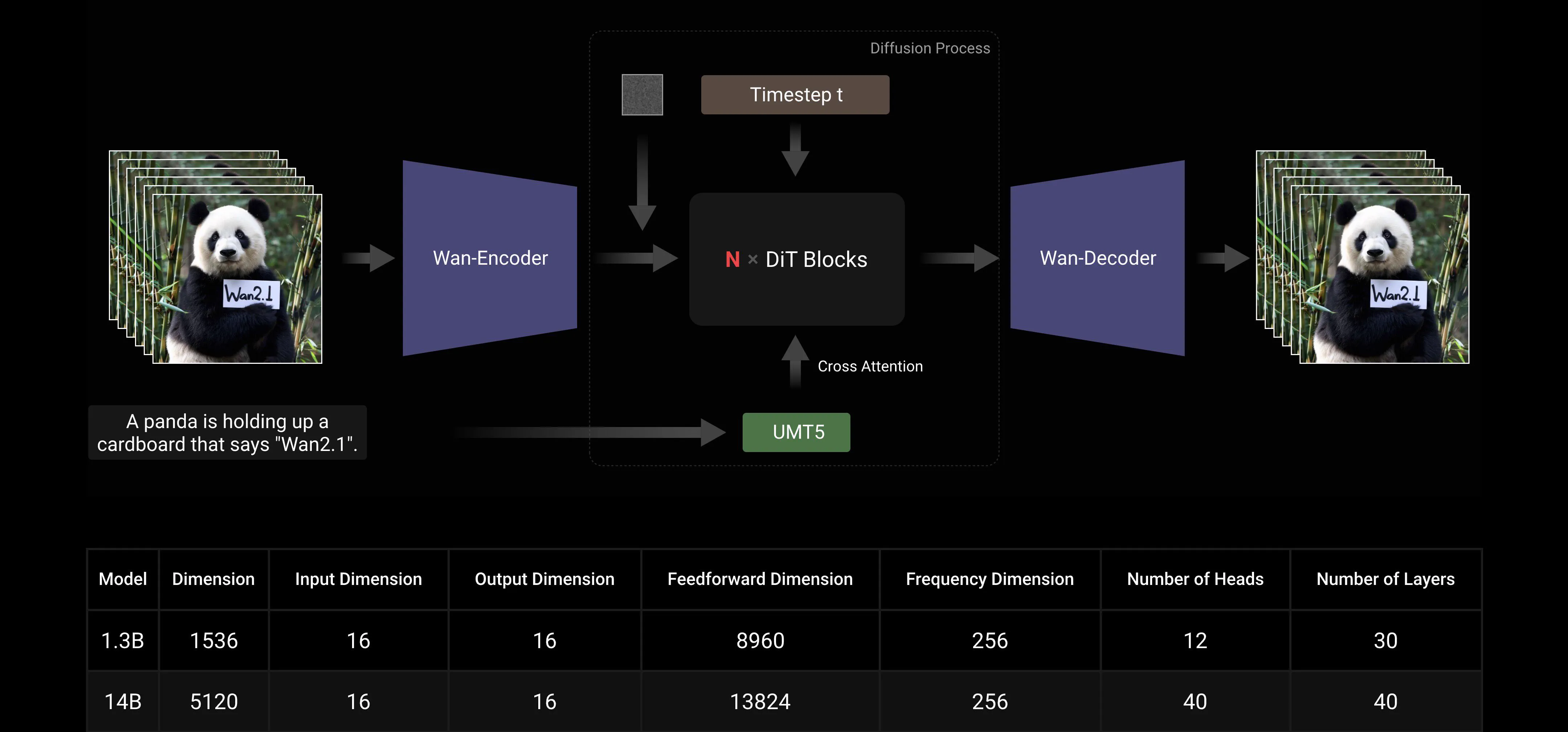
Modelltraining und Inferenzeffizienzoptimierung: Während der Trainingsphase verwenden wir für die Text- und Video-Codierungsmodule eine verteilte Strategie, die Data Parallelism (DP) und Fully Sharded Data Parallelism (FSDP) kombiniert. Für das DiT-Modul verwenden wir eine hybride Parallelstrategie, die DP, FSDP, RingAttention und Ulysses integriert. Während der Inferenzphase müssen wir, um die Latenz bei der Generierung eines einzelnen Videos mit mehreren GPUs zu reduzieren, Collective Parallelism (CP) für die verteilte Beschleunigung auswählen. Zusätzlich ist bei großen Modellen auch ein Modellslicing erforderlich.

Quelloffene Community-freundlich
Wan AI hat mehrere Mainstream-Frameworks auf GitHub und Hugging Face vollständig unterstützt. Es unterstützt bereits Gradio-Erfahrung und parallel beschleunigte Inferenz mit xDiT. Die Integration mit Diffusers und ComfyUI wird ebenfalls schnell umgesetzt, um Entwicklern eine einfache Inferenzbereitstellung mit einem Klick zu ermöglichen. Dies senkt nicht nur die Entwicklungsschwelle, sondern bietet auch flexible Optionen für Benutzer mit unterschiedlichen Anforderungen, sei es für schnelle Prototypenentwicklung oder effiziente Produktionsbereitstellung.
Quelloffene Community-Links:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Anhang: Wan AI-Modell-Demo-Showcase
Das erste Videogenerierungsmodell, das die chinesische Textgenerierung unterstützt und gleichzeitig die Text-Effekt-Generierung in Chinesisch und Englisch ermöglicht:
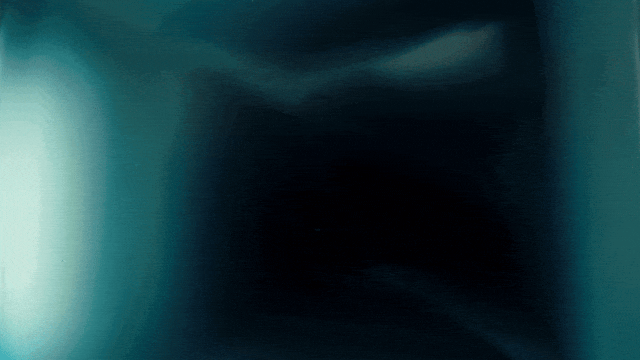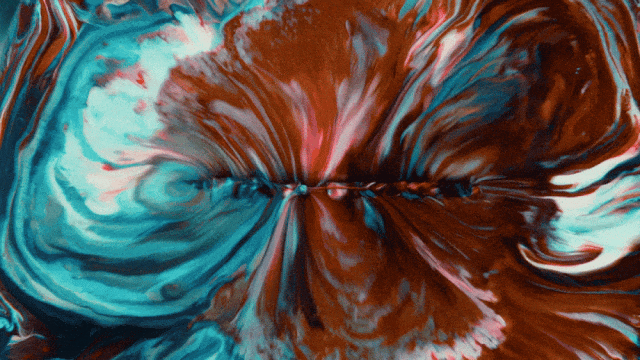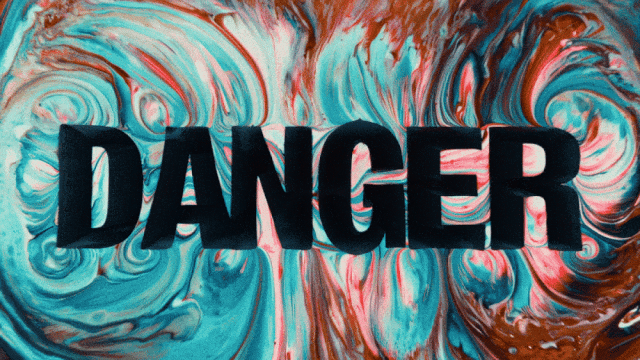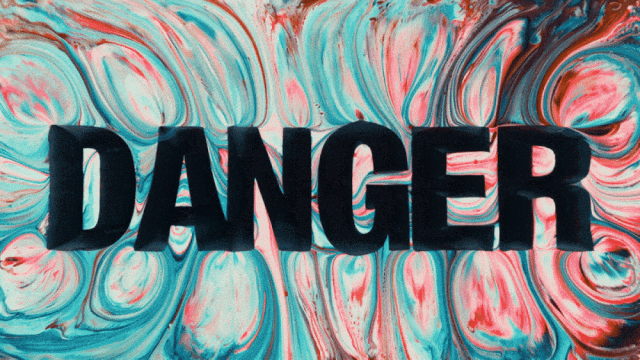
 Stabilere und komplexere Bewegungsgenerierungsfähigkeiten:
Stabilere und komplexere Bewegungsgenerierungsfähigkeiten:

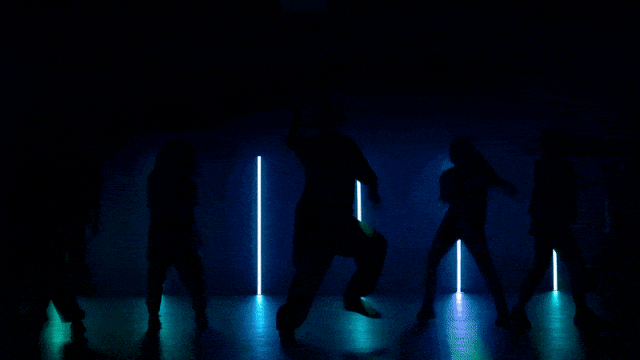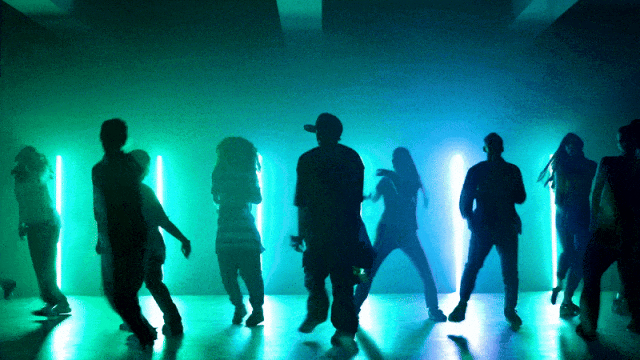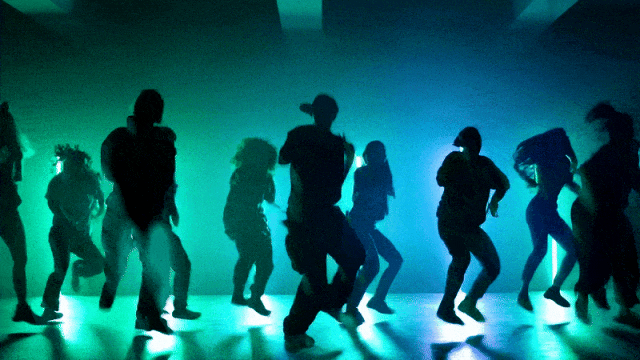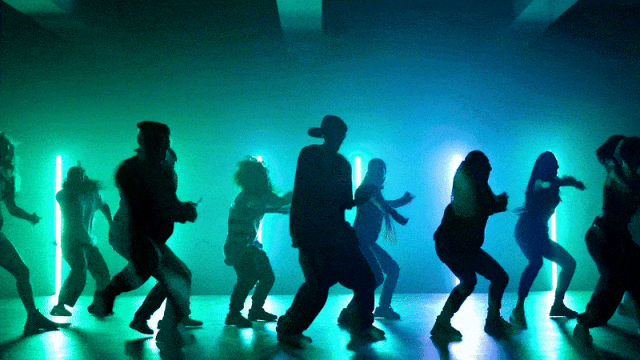 Flexiblere Kamerasteuerungsfähigkeiten::
Flexiblere Kamerasteuerungsfähigkeiten::

 Fortgeschrittene Texturen, diverse Stile und mehrere Seitenverhältnisse:
Fortgeschrittene Texturen, diverse Stile und mehrere Seitenverhältnisse:
 Bild-zu-Video-Generierung, die die Erstellung kontrollierbarer macht:
Bild-zu-Video-Generierung, die die Erstellung kontrollierbarer macht:

